
Configuration des sécurités de SQL Server 7.0 et de IIS
par John D. Lambert
Comment améliorer les sécurités et les performances de la connexion.
L'utilisation des configurations par défaut rend l'installation de Microsoft IIS
et de SQL Server 7.0 plus rapide et plus simple, mais en acceptant les valeurs
par défaut pour l'authentification sur SQL Server 7.0, on peut mettre en danger
la sécurité des données du serveur. Etant donné que SQL Server 7.0 comporte certaines
failles dans sa sécurité, l'authentification Windows 2000 ou Windows NT constitue
peut-être un meilleur choix que celle de SQL Server. La plupart du temps, les
gens utilisent IIS avec des pages Web qui se connectent à SQL Server via des liens
ODBC dans le modèle de programmation ADO. Cette méthode fonctionne, mais ce n'est
pas la plus efficace. Dans cet article, je présente quelques astuces que l'on
peut utiliser pour améliorer les sécurités et la connexion à SQL Server.
On a deux possibilités lorsqu'on configure l'authentification dans SQL
Server 7.0 : le mode Windows NT et le mode mixte
Abordons avant tout les différentes possibilités d'authentification. On a deux
possibilités lorsqu'on configure l'authentification dans SQL Server 7.0 : le mode
Windows NT et le mode mixte. Microsoft recommande fortement l'authentification
NT. En fait, SQL Server 2000 utilise par défaut l'authentification NT à l'installation.
Le white paper "Microsoft SQL Server 7.0 Security " (http://www.microsoft.com/sql/techinfo/dupsecurity.document)
contient plus d'informations sur la mise en place des authentifications. Les outils
de piratage disponibles sur le Web permettent à tout employé malhonnête, depuis
l'intérieur de vos firewalls, ou à n'importe qui capable de passer ces firewalls,
de remplacer le mot de passe de votre compte administrateur, de se connecter,
de créer un nouveau compte ayant des privilèges d'administrateur, se déconnecter
et de remplacer votre mot de passe précédent. Ainsi, si l'authentification SQL
Server reste active, on permet à un intrus potentiel d'acquérir le contrôle total
de la base de données. La réponse officielle de Microsoft à cette vulnérabilité
est qu'il faut entièrement désactiver l'authentification SQL Server. Pour utiliser
SQL Server avec une authentification NT, il faut d'abord créer des comptes NT
que les pages Web pourront utiliser, puis donner les autorisations SQL Server
dont elles auront besoin. Ensuite, on convertit les pages pour qu'elles puissent
utiliser les comptes NT correctement mappés lorsque les utilisateurs se connectent
anonymement. Après avoir rendu les pages Web compatibles avec l'authentification
NT, reconfigurez SQL Server pour utiliser uniquement cette authentification NT.
Faites ces modifications sur votre serveur de développement dans un premier temps,
et, après vous être assuré que la configuration fonctionne correctement, reproduisez
ce processus sur les serveurs de production.
Pour rendre une page Web compatible avec les comptes NT, il faut que le code puisse
utiliser des connexions sécurisées, comme je vais le démontrer. Si on utilise
des objets de connexion que l'on a intégrés à des DLL, et que l'on a installé
ces DLL dans MTS (Microsoft Transaction Server) en tant que composant COM+, le
travail sera plus facile que si on a codé les connexions dans chaque page Web.
Il ne vous reste plus alors qu'à modifier le code source pour utiliser une chaîne
de connexion sécurisée, recompiler le code et mettre à jour le composant MTS.
Si votre site Web utilise des objets de connexions ADO sur chaque page, il faut
éditer chacun d'entre eux. Si vous avez de nombreuses pages, un outil de recherche
et de remplacement fonctionnant au niveau d'une arborescence de répertoires peut
vous faire gagner du temps.
| Optimisez les sécurités et la connexion à SQL Server et IIS Voici un résumé des choses que l'on peut mettre en oeuvre pour optimiser la sécurité et la connexion à SQL Server. 1. Utiliser des authentifications uniquement Wi Lire l'article
Se familiariser avec l’instruction SQLL'instruction Select est incontournable…
Pour exécuter une requête SQL, l'utilisation de l'instruction Select est incontournable.
C'est pourquoi, j'entame cette série d'articles consacrée aux fondements du langage
SQL par un article qui présente la syntaxe de l'instruction Select.
Architecture Profusion : la fin des limites ?Un grand nombre d'entreprises exécutent NT Server sur processeurs Intel. Ce choix est intéressant à plusieurs titres : le matériel est meilleur marché, l'éventail des constructeurs et très large, le catalogue applicatif est extrêmement important… mais les systèmes plafonnent à 4. La situation change avec la nouvelle architecture Profusion d'Intel. NT Server progresse fortement et les entreprises sont de plus en plus nombreuses à déployer sur NT Server des applications telles que data mining, progiciels de gestion (ERP) et serveurs de terminaux, tournant sur des serveurs SMP à architecture Intel. Parallèlement elles sont plus exigeantes sur les niveaux d'évolutivité des systèmes, en vue d'améliorer les performances. Or le serveur SMP à quatre voies ne peut plus répondre à ces besoins. Pour apporter une solution à cette situation, Intel a donc mis au point un nouveau standard, le système SMP baptisé Profusion, une méthode standardisée permettant de placer huit processeurs dans une CPU. On trouve sur le marché quantité de machines à 4 voies et plus, mais elles utilisent des architectures propriétaires. Un serveur SMP à 8 voies vraiment évolutif permet aux applications comme SAP et SQL Server 7.0 d'atteindre de meilleures performances.Le support de huit processeurs par l'architecture Intel Profusion est unique et il est important de comprendre cette nouvelle architecture avant d'évaluer et d'acheter un nouveau serveur SMP à 8 voies. Quelle est donc cette nouvelle architecture, ses composants, ses perspectives ? Lire l'article
Une meilleure conception des moteurs de recherchepar David Jones
Utilisez la fonction de recherche documentaire de SQL Server 7.0 pour concevoir des bases de données pouvant être consultées sur le Web
Que vous fassiez des recherches pour un exposé ou que vous
recherchiez un numéro de téléphone, ou encore que vous ne fassiez que surfer,
vous utilisez probablement un moteur de recherche Internet quotidiennement. Pour
répondre à la demande d'informations récupérables, de nombreuses
entreprises conçoivent des sites Web utilisant des bases de données
relationnelles en arrière-plan et sur lesquels les utilisateurs peuvent
effectuer des recherches dynamiques. En notre qualité d'administrateurs de
bases de données et de développeurs d'applications, nous devons concevoir de
meilleurs mécanismes permettant à l'utilisateur de rechercher des informations
sur l'entreprise, telles que les bilans pour les actionnaires, les communiqués
de presse, les catalogues produits, etc... La fonction de recherche documentaire
de SQL Server 7.0 peut représenter la réponse. Le moteur de recherche
documentaire de SQL Server permet des recherches rapides, et offre des
fonctionnalités avancées de recherche de texte, très utiles dans un
environnement d'entreprise. Vous utilisez probablement un moteur de recherche Internet quotidiennement Avec les premières versions de SQL Server, on était limité à des requêtes sur de larges blocs de texte en utilisant LIKE dans une instruction SELECT. Mais l'instruction LIKE est limitée, car elle ne peut établir de correspondance qu'avec des séquences de caractères. En outre, si on utilise l'instruction LIKE avec un signe pourcent (%) avant et après la chaîne recherchée, on génère une analyse de table très longue. La plupart des utilisateurs ont besoin de fonctions de recherche plus avancées, produisant des résultats immédiats après qu'ils aient appuyé sur la touche Entrée. Avec SQL Server 7.0 et les versions ultérieures, on peut toujours utiliser l'instruction LIKE si on le souhaite, mais on peut désormais aussi utiliser une nouvelle option de syntaxe et indexer les données. Au lieu d'utiliser les index stockés dans la base de données, le moteur de recherche documentaire utilise Microsoft Search Service pour répertorier ces index sur le disque dur du serveur. Lorsqu'on sélectionne l'option Full-Text Search dans la Configuration personnalisée de SQL Server, le processus d'installation installe automatiquement Microsoft Search Service. Toutefois, ce service n'est disponible que pour les systèmes Standard et Enterprise sous Windows 2000 ou Windows NT, et non dans les versions poste de travail ou Windows 9x. Microsoft Search Service intègre deux fonctions distinctes : conception et peuplement du catalogue de recherche documentaire, et traitement de la recherche. Pour installer le moteur de recherche documentaire après avoir installé SQL Server, il faut réexécuter l'installation à partir du CD-ROM de SQL Server 7.0. Dans la boîte de dialogue Select Components (Sélectionner les composants), sélectionnez L'option Full-Text Search, comme cela est indiqué dans la figure 1, puis redémarrez. Seul SQL Server 7.0 fonctionnant sous NT Server prend en charge la recherche documentaire. L'environnement NT Server Enterprise Edition clusterisé ne supporte pas encore la fonction de recherche documentaire de SQL Server. De fait, Microsoft prendra en charge cette fonction dans un environnement clusterisé dans SQL Server 2000. Lire l'article
Comment tout savoir sur SQL Server 2000La nouvelle version atteint de nouveaux sommets
Remarque : Les auteurs ont basé leurs articles SQL Server 2000 sur des versions
antérieures à la Bêta 2. Aussi, il se peut que vous remarquiez quelques différences
entre la Bêta 2 et le comportement ou les interfaces décrits dans cet article.
En particulier, veuillez noter que la fonction vues indexées ne sera disponible
que dans SQL Server 2000 Enterprise Edition. Toutefois, on peut installer Entreprise
Edition sur un serveur NT 4 ou Windows 2000 (W2K). On n'est pas obligé d'utiliser
NT 4.0 Enterprise ou W2K Advanced Server.
Améliorez les performances base de données avec l’assistant d’optimisation des indexpar Itzik Ben-Gan
SQL Server 2000 : Le modèle OIMUn groupe d'éditeurs et d'entreprises utilisatrices a formalisé les types de métadonnées
pour les entrepôts de données. C'est devenu l'OIM (Open Information Model)
Avant les efforts de normalisation de Microsoft, les éditeurs et la communauté
informatique ne parvenaient guère à se mettre d'accord sur le type de métadonnées
qu'un entrepôt de données devait contenir.
Intégrité référentielle avec SQL Serverpar Kalen Delaney
Les 7 étapes vers le data warehouseLes data warehouses sont un rêve pour les analystes : toute l'information concernant
les activités de l'entreprise est regroupée en un seul lieu et prête à être utilisée
par un ensemble cohérent d'outils d'analyse. Mais comment transformer le rêve
en réalité ?
Pour atteindre ce Nirvana des décideurs qu'est le data warehouse, il faut tout
d'abord bien penser le système. Vous devez comprendre le type de questions que
les utilisateurs vont lui poser (par exemple, combien de nouveaux clients par
trimestre ou quel segment de marché achète le plus d'environnements de développement
d'applications dans la région Ouest) car la raison d'être des systèmes de data
warehouse est de fournir aux décideurs l'information adaptée et à jour dont ils
ont besoin pour faire les bons choix.
SQL Server 2000 : vers les sommetsImaginez que vous pouvez construire la maison de vos rêves. Pas de problème de
budget, mais vous voulez emménager le plus vite possible. Dans ce cas, il vous
faudra choisir entre avoir la perfection avant d'emménager et prendre possession
de la maison le plus vite possible. Vous prendrez probablement du temps pour concevoir
les fondations et les pièces essentielles, quitte à ajouter une aile ou à aménager
les combles par la suite.
Le processus d'évolution de SQL Server ressemble un peu à la construction de cette
maison. Il y a plusieurs années, Microsoft a réuni plusieurs des meilleurs spécialistes
mondiaux des bases de données (de Microsoft et d'ailleurs) et leur a demandé de
créer la base de données de leurs rêves. On peut considérer SQL Server 7.0 comme
les fondations de ce projet.
Utiliser Microsoft Repositorypar Patrick Cross et Saeed Rahimi
SQL Server 7.0 Réplication personnaliséepar John D. Lambert
Réplication bidirectionnelle avec SQL Server 7.0par Baya Pavliashvili
Indexer pour optimiser les performances des trispar Dusan Petrovic et Christian Unterreitmeier 
Windows 2000 et SQL Server
par Michael Otey 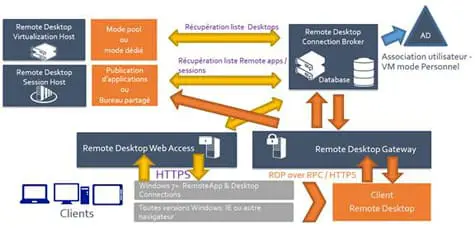
XML et SQL Server 2000par Paul Burke
L'une des fonctionnalités les plus attendues de SQL Server 2000, le support de XML, est également l'une des plus floues en termes de valeur pratique immédiate. Personne n'a échappé au battage médiatique concernant ce langage, qui constituerait une passerelle entre tous les langages, et presque tous les systèmes de gestion de bases de données relationnelles (SGBDR) affirment désormais prendre en charge XML. Mais où, quand et pourquoi utiliser XML ? XML permet de publier des types de données indépendamment des plates-formes, facilitant ainsi l'interopérabilité et le commerce électronique XML, un standard Internet d'échange d'informations, permet de publier des types de données indépendamment des plates-formes, facilitant ainsi l'interopérabilité et le commerce électronique. XML sépare également les données des informations de présentation à l'intérieur des pages Web ; on dispose ainsi d'un moyen standard pour définir et échanger des données entre applications et bases de données. (L'encadré "XML, le standard à la mode", décortique les avantages qu'il y a à utiliser XML pour séparer les données de leur présentation). En tant que langage de définition de pages, le principal intérêt de XML vient soit de l'acceptation générale d'un langage particulier, défini dans XML, soit de l'acceptation générale de XML et de la disponibilité des utilitaires, d'outils et de l'infrastructure permettant de prendre en charge son utilisation. Même si XML comporte plusieurs excellents langages définis (tels que BizTalk, DSML [Directory Services Markup Language], et SOAP [Simple Object Access Protocol]), ce n'est pas la panacée pour tout le monde, surtout si on travaille dans un environnement Microsoft pur et dur, et qu'on développe des applications Windows 32 bits. Pour le transfert de données via un LAN, les ensembles de résultats ADO représentent le choix évident. Cependant, à l'heure de l'Internet, rares sont les entreprises qui travaillent en circuit fermé. Et même à l'intérieur des entreprises, il n'est pas rare de trouver différents types de serveurs, plates-formes ou langages. Bien que SQL Server 2000 soit la première version de SQL Server à proposer le support de XML, la fonction de prévisualisation XML de Microsoft fonctionne avec les versions 7.0 et 6.5. (on peut télécharger cette fonction de prévisualisation depuis le site Web SQL Server de Microsoft, à l'adresse suivante : http://msdn.microsoft.com/workshop/xml/articles/xmlsql/). On peut également intégrer le support de XML dans SQL Server 7.0, 6.x et 4.2 en créant des procédures cataloguées étendues et des procédures cataloguées standard, quoique les procédures cataloguées standard puissent faire baisser les performances pour des ensembles de données de grande taille et de structure complexe. En outre, certaines fonctionnalités de SQL Server 7.0, telles que la recherche documentaire sur texte intégral, permettent de stocker du code XML comme du texte. Quelles sont alors les fonctions qui rendent SQL Server 2000 officiellement compatible XML ? En général, on peut demander deux sortes de XML à une base de données : le XML statique, stocké dans la base de données, et le XML dynamique, généré par les données présentes dans la base de données. Même la première version d Lire l'article Les plus consultés sur iTPro.fr
Articles les + lus
Rançongiciels et IA : les attaques gagnent en efficacité en ciblant l’humain 
Pourquoi les PME ne peuvent plus se permettre de négliger la sécurité de leur parc d’imprimantes 
Deepfakes : la France dans le top 10 des pays les plus touchés par les fraudes 
Cybersécurité : les entreprises françaises réclament un durcissement inédit de la réglementation 
Cyber risques et IA : 78% des RSSI pointent une déconnexion inquiétante des dirigeants À la une de la chaîne Data
X
Gérer le consentement aux cookies
Fonctionnel Toujours activé
Le stockage ou l’accès technique est strictement nécessaire dans la finalité d’intérêt légitime de permettre l’utilisation d’un service spécifique explicitement demandé par l’abonné ou l’internaute, ou dans le seul but d’effectuer la transmission d’une communication sur un réseau de communications électroniques.
Préférences
Le stockage ou l’accès technique est nécessaire dans la finalité d’intérêt légitime de stocker des préférences qui ne sont pas demandées par l’abonné ou la personne utilisant le service.
Statistiques
Le stockage ou l’accès technique qui est utilisé exclusivement à des fins statistiques.
Le stockage ou l’accès technique qui est utilisé exclusivement dans des finalités statistiques anonymes. En l’absence d’une assignation à comparaître, d’une conformité volontaire de la part de votre fournisseur d’accès à internet ou d’enregistrements supplémentaires provenant d’une tierce partie, les informations stockées ou extraites à cette seule fin ne peuvent généralement pas être utilisées pour vous identifier.
Marketing
Le stockage ou l’accès technique est nécessaire pour créer des profils d’internautes afin d’envoyer des publicités, ou pour suivre l’internaute sur un site web ou sur plusieurs sites web ayant des finalités marketing similaires.
|