

XML et SQL SERVER
Les informations échangées entre les différents systèmes, les différentes applications le sont de plus en plus auSQL Server, se sont adaptées. En effet, SQL Server à, entre autre, pour objectif de faciliter le travail avec les données. Pour cela, SQL Server dispose d'un ensemble d'instructions pour extraire des informations relationnelles au format XML ou bien l'opération inverse qui consiste à lire des données au format XML afin de stocker les informations dans une structure relationnelle classique.
Ces 2 étapes sont nécessaires et permettent de confier au moteur de base de données la plupart des transformations depuis ou vers le format XML à SQL Server. Mais SQL Server propose plus en offrant la possibilité de créer des colonnes de type XML. En intégrant directement les informations XML dans la structure relationnelle classique, SQL Server offre plus de souplesse en terme de stockage. Ce type XML est bien plus qu'un simple champ texte car SQL Server rend possible l'indexation des colonnes de type XML mais également la mise à jour, l'ajout et la suppression de données dans le document XML lui-même.
Ce sont ces trois fonctionnalités (extraire les informations au format XML, importer des données XML, stocker des données au format XML) de SQL Server qui sont exposées ci-dessous.

Le Guwiv présente Windows SteadyState
Le Guwiv présente un outil méconnu de Windows Vista, Windows SteadyState. L’équivalent de Shared Computer Toolkit sous Windows XP permet de sécuriser gratuitement un ordinateur accessible en libre service comme un PC dans un cybercafé par exemple. Ce produit fonctionne aussi avec Windows XP.
Le site revient aussi sur le Tech Ed 2008 et met à la disposition des internautes, les diaporamas PowerPoint de la présentation de J. Peter Bruzzese (MCSE et MCITP) sur les trucs et astuces de Vista, tels que les raccourcis clavier ou le réglage des différents menus.

Windows Server 200 Hyper-V
La firme de Redmond vient de rendre disponible au téléchargement le moteur de virtualisation Windows Server 200 Hyper-V.
Véritable extension de Windows Server 2008, l’hyperviseur doit permettre aux entreprises de faire tourner plusieurs systèmes d’exploitation sur une seule machine physique.
Lire l'article
Personnalisation de l’affichage dans Active Directory
Dès sa conceptionActive Directory est une base de données constituée d’attributs et de classes. Une classe est un regroupement d’attributs constituant un objet. Le schéma, qui est le squelette de la base de données Active Directory, n’est pas figé, celui-ci peut être facilement étendu. Cependant, beaucoup d’administrateurs se demandent comment afficher un attribut qui aurait été ajouté au schéma Active Directory. Voici comment personnaliser cet affichage.
Lire l'article
Périmètre de sécurité
Voilà encore quelques années, une composante du périmètre de sécurité, lequel n’est qu’un élément de la sécurité. Voici les points importants d’un périmètre de sécurité, et une checklist, utiles pour planifier ledit périmètre dans un environnement moderne, de plus en plus connecté.
Lire l'article
La haute disponibilité à votre portée dans Exchange 2007
Exchange Server 2007, vous pouvez trouver des solutions qui ne vont pas « faire exploser » votre budget et n’exigeront pas de votre équipe Exchange qu’elle passe un doctorat en clustering. Nous allons commencer ici notre examen des solutions de haute disponibilité d’Exchange 2007 par une présentation générale. Dans les prochains articles, nous explorerons plus en détail ce sujet avec la configuration de la réplication locale en continu (LCR) et de la réplication continue en cluster (CCR) dans Exchange 2007.
Lire l'article
actu Windows semaine 26
La société de conseil et de services spécialisée en Business Intelligence et technologies objet et Web, Homsys Group, a atteint le niveau de certification Gold Certified Partner dans le programme de partenariat Microsoft. Ce niveau d’engagement leur donne un accès privilégié aux ressources et support techniques, commerciaux et marketing de la firme de Redmond. Ils […]
Lire l'article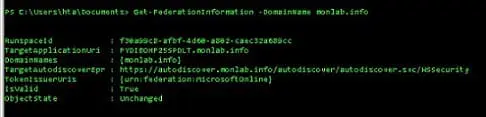
Windows Server 2003 SP2
La dernière contribution de Microsoft à la période de fêtes fut Windows Server 2003 Service Pack 2 (SP2). Comme les packs de service Microsoft nous y ont habitués, l’administrateur IT.
Lire l'article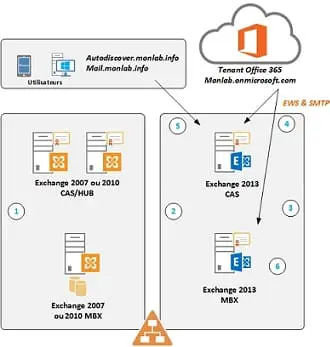
La Cadim relaie l’engagement de Microsoft sur l’interopérabilité.
La CADIM propose un lien vers le communiqué de presse de Microsoft.
Lire l'article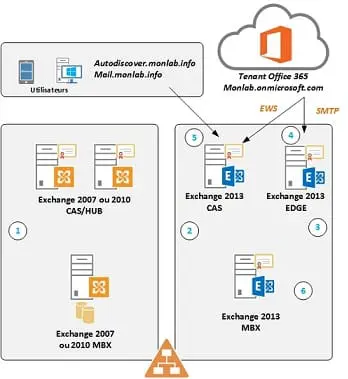
Le DUG aux TechDays 2008
Le DUG a annoncé sa présence au salon des Microsoft TechDays 2008
Lire l'article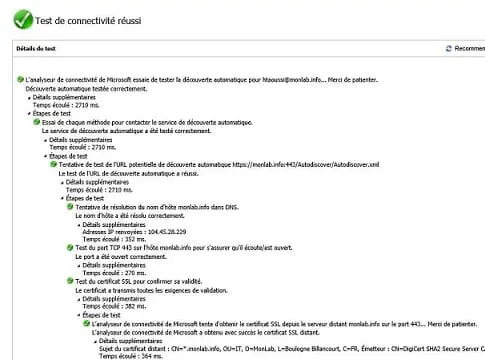
Devenez incolable sur Windows Server 2008
Le GUWISE vous propose de devenir incollable sur le nouveau Windows Server 2008, à travers le site Technet. Au programme : Webcast, présentations, et téléchargements de la « Release Candidate ».

Connexion sécurisé intersites
L’un des blogs d’ISAServer (celui de Thierry Nyembo) évoque les problèmes d’incompatibilité lors de la mise en place d’une connexion sécurisé intersites.
Lire l'article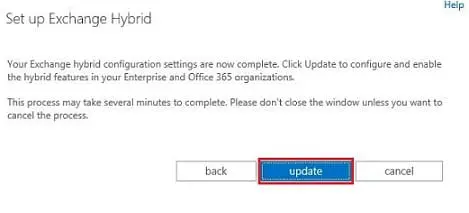
Webcast consacré à la migration sur Exchange 2007
Le GU-CU vous propose d’assister à un webcast le jeudi 20 mars. Cette réunion web sera animée par le MVP Laurent Teruin qui reviendra sur la migration d'Exchange Server 2000 à Exchange Server 2007. Plus d’informations sur cette page
Lire l'article
Du nouveau pour le GuVirt !
Ouvert début juin, le site du GuVirt a pour objectif d’atteindre une centaine de membres d’ici un an. De plus, une réunion sera organisée à la rentrée prochaine et portera sur Hyper-V, l’hyperviseur de Microsoft.
Plus récemment, un guide sur les « Best Practices » pour la virtualisation avec Active Directory vient d’être mis en ligne sur le site.
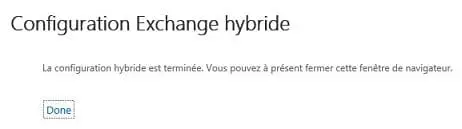
GUE : « faire tourner Exchange sur Windows Server 2008 » !
Le briefing d'été du L'article complet à cette adresse.
Lire l'article
Congrès européen du Common
Le congrès européen du Common s’est tenu à Barcelone du 17 au 20 mai 2008. Plus d’information sur cette page
Lire l'article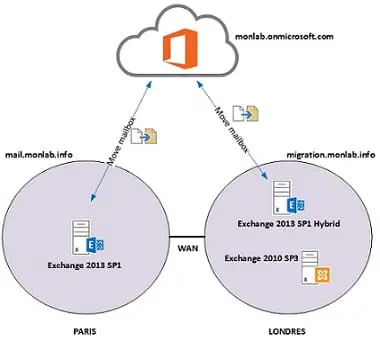
Tout sur IE8
Le Guwiv propose de vous préparer à Internet Explorer 8 et vous donne un ensemble de liens pour tout savoir sur le prochain explorateur.
Dans les autres news, le site revient sur la journée du 26 mai dédiée à la « journée Windows » et présente la Beta de SysInternals Live qui permet d'exécuter les outils SysInternals directement depuis le Web.

Réunion du GUSS : le décisionnel à l’honneur !
Fin mai, s’est tenue la dernière réunion du GUSS (Groupe des utilisateurs de SQL Server) à Paris. Cette rencontre trimestrielle, qui est toujours l’occasion d’échange d’informations techniques, a rencontré un très vif succès, puisque plus de 50 personnes étaient présentes dans la salle.
Cette réunion a mis à l’honneur un sujet d’actualité : le décisionnel ! D’abord un petit retour sur le « pourquoi » du décisionnel, avant de s’engouffrer au fur et à mesure dans son évolution et l’offre de Microsoft. Cette session – panorama découverte de la Business Intelligence avec SQL Server - fut animée par Arian Papillon, président du GUSS et Sébastien Madar, Mcnext / GUSS.
L’offre décisionnelle de Microsoft s’est fortement développée dès 1999.
Les objectifs : mieux piloter l’activité en disposant d’une information simple, ciblée, pertinente, disponible, synthétique et détaillée ; répondre aux contraintes qualité en fournissant des indicateurs ; enfin, rendre l’information accessible grâce à des accès variés et en permettant une certaine autonomie !
Quant à son évolution, on peut parler de 3 générations. La 1ère génération, avec SQL Server 7.0, offre OLAP Services, un nouvel ETL (DTS) et une nouvelle philosophie « le décisionnel pour tous ». La 2ème génération, avec SQL Server 2000, s’améliore : OLAP Services devient Analysis Services (ajout du datamining) et Reporting Services (add-on) est téléchargeable. Enfin, la 3ème génération, avec SQL Server 2005 dans un premier temps, offre une refonte d’Analysis Services, plus de datamining, une nouvel ETL : SSIS, Reporting Services intégré désormais à l’offre, un nouvel environnement de développement (Visual Studio 2005) et de nouveaux outils de restitution. Avec l’arrivée de SQL Server 2008, cette génération se modifie, on parle de « continuité et amélioration » de SQL Server 2005 avec une amélioration des outils et des performances pour SSAS, SSRS, et une nouvelle interface orientée utilisateur.
Le décisionnel s’installe donc en force ! La business intelligence s’adapte ainsi aux rôles et aux missions des collaborateurs (contributeurs, analystes, management). Chacun a droit d’avoir des indicateurs (alertes). Pour cela, le reporting structuré a sa place et représente 80% des besoins d’accès à l’information dans l’entreprise. Les rapports sont donc constitués selon des règles et formats prédéfinis.
Enfin, il faut permettre aux utilisateurs de concevoir eux-mêmes des rapports simples. La navigation dans les données n’est pas en reste, grâce à OLAP, et les mesures (quantité, CA, marges, délais..) sont ainsi croisées avec les paramètres clients, temps, produits, géographie. La datamining prend également toute sa valeur : ce processus d’analyse d’un grand volume de données pour en extraire les tendances ou corrélations avec les différents algorithmes est primordial ! Quant aux tableaux de bord et portail décisionnel, le choix s’affine et est bien réel (indicateurs de performances, plusieurs sources, ERP, CRM, OLTP…).
Concevoir une base de données dédiée à l’analyse est essentielle ! La base de données OLTP est mal adaptée à l’analyse, e

Isoler une chute de performances sur un environnement Exchange
Lorsqu’on travaille sur des serveurs Exchange, il arrive ponctuellement de rencontrer des erreurs. La plupart du temps, celles-ci sont identifiées par un message d’erreur ou un effet de bord identifiable et reproductible, et disons que dans ce cas précis, c’est déjà une chance.D’autres sont plus intangibles et ne provoquent pas d’erreurs particulières. Généralement, on constate une chute de performances, ou une absence ponctuelle de connectivité. Bref, aucun indice qui permette de mettre sur une quelconque piste. Souvent, ce problème est ignoré. On mise sur le fait qu’il soit conjoncturel ou qu’il ne s’étende pas. La plupart du temps, on traite les priorités en se disant que le problème finira tôt ou tard à disparaître de lui-même, ou qu’il est issu de l’imagination du collaborateur qui l’a signalé.
Or, il arrive souvent que ce ralentissement soit un signe avant-coureur d’une situation beaucoup plus sévère, et que n’en tenant pas compte, vous vous retrouviez dans une position plus critique avec des utilisateurs et une direction impactée par cette situation. C’est dans ce cadre que j’ai décidé d’écrire cet article, afin de partager avec vous les méthodes et outils qui vous permettront d’établir un plan de diagnostic efficace pour isoler le ou les facteurs en cause. D
eux éléments primordiaux sont à considérer dès qu’on vous signale ou que vous constatez un incident de ce type :
• Ne touchez à rien. Tant que vous n’avez pas déterminé l’origine exacte de l’incident, la modification des paramètres d’un ou de plusieurs composants ne ferait que rendre plus complexe le diagnostic. D’expérience, il faut mieux éviter les opérations de type « et si je modifiais ce paramètre, est-ce que ce serait mieux ? »
• Communiquez et entourez-vous d’expertise. La plupart du temps, les problèmes rencontrés proviennent de plusieurs composants, qui, mal assemblés ou dysfonctionnels sont à l’origine du problème. Or, ces composants provenant d’éditeurs différents, vous vous retrouverez rapidement en échec par les supports éditeurs traditionnels où ceux-ci ne pourront s’engager plus en avant sur une brique qu’ils ne maîtrisent pas. Les autres types de support, comme les groupes de discussion ou vos contacts personnels ne seront pas également d’une grande aide, car le plus souvent votre environnement est spécifique, et que malheureusement, la situation n’est pas reproductible d’un environnement à un autre.
Si vous ne traitez vous-même l’incident, la meilleure solution consiste à faire appel à une société de services partenaire de Microsoft capable de vous fournir de sérieuses références dans le cadre de situations similaires et disposant d’expertise dans tous les composants dont est constitué votre système de messagerie. Cette solution aura pour effet également que la pression de vos utilisateurs et votre direction soit redirigée sur ce fournisseur et non sur vos équipes ou vous-même.
Les plus consultés sur iTPro.fr
- Le futur de la cryptographie post-quantique
- Couchbase lance AI Data Plane pour industrialiser l’IA agentique
- Windows 11 : Microsoft généralise le point-in-time restore pour accélérer la remise en service des PC
- Deepfakes et IA : 64% des Français pensent savoir les détecter, mais la confiance reste fragile
À la une de la chaîne Tech
- Couchbase lance AI Data Plane pour industrialiser l’IA agentique
- Windows 11 : Microsoft généralise le point-in-time restore pour accélérer la remise en service des PC
- Computex 2026 : 5 signaux forts à retenir
- La chaîne d’approvisionnement, point de rupture récurent du SI
- Microsoft Build 2026 : contre-offensive des modèles maison face à OpenAI et Anthropic