
Actu SQL sem 26
Un atelier pour utiliser SQL Server 2008 au maximum !
L’atelier SQL Server 2008 vient de se tenir à Paris. L’occasion pour les experts Microsoft France de recevoir les professionnels de l’informatique - décideurs informatiques, les architectes, développeurs – pour approfondir la technologie SQL Server 2008.
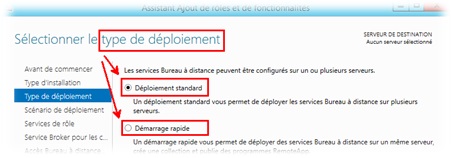
Régler la performance du serveur Web i5/OS
Le fameux « Time is money » des anglo-saxons, devenu chez nous « Le temps c’est de l’argent », s’applique tout particulièrement à votre activité professionnelle sur le Web.
Malheureusement, régler la performance du Web relève plus de l’art que de la science, et l’art ne peut être bousculé. Il faut d’abord trouver tous les paramètres et attributs pertinents. Vous allez donc examiner les écrans passifs et ceux d’iSeries Navigator, vous promener sur la console d’administration WAS (WebSphere Application Server) et vous plonger dans EWLM (Enterprise Workload Manager) pour trouver les bons paramètres.
Mais il vous restera encore à déterminer ce qu’ils doivent être. En effet, ce qui fonctionne bien dans un contexte traditionnel pourrait bien faire le contraire dans votre environnement Web, et la perspective d’ajouter WAS, IBM WebSphere Portal et des bases de données, est suffisante pour vous faire renoncer.
| Contenu compémentaire ISERIES NAVIGATOR : les nouveauté de la v5r4 |
Lire l'article
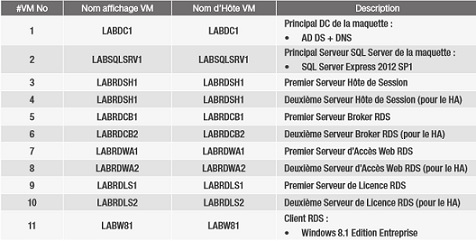
La haute disponibilité dans la boîte
En janvier 2006, Dave Thompson, vice-président de la division haute disponibilité et étudier leur impact possible sur vos plans de déploiement. Votre entreprise peut trouver des avantages dans la redondance procurée par les rôles de serveur ou dans les nouvelles fonctionnalités de réplication locale en continu (LCR) et de réplication continue en cluster (CCR).

Les solutions de haute disponibilité avec Exchange 2007
les systèmes de messagerie par les entreprises de toute taille. Ce besoin est motivé par la criticité croissante de la messagerie électronique au sein des entreprises et des applications métier. Si la notion de disponibilité minimale varie selon les entreprises, tous les responsables informatiques souhaitent atteindre un niveau élevé de disponibilité. Les entités pour lesquelles la messagerie est critique choisissent souvent de concevoir un système de messagerie hautement disponible afin d'atteindre les objectifs définis dans le cadre du niveau de service requis (SLA). Il faut distinguer deux aspects différents qui sont la continuité de service et la reprise en cas d’incident. On y associe aussi souvent les notions de RTO (Recovery Time Objectives), c'est-à-dire de temps de récupération des données et de RPO (Recovery Point Objectives), c'est-à-dire l’impact sur les données et l’acceptation de retour en arrière et donc potentiellement la perte de données.
RA et PCA, deux aspects complémentaires La mise en place d’un plan de continuité d’activité (PCA) sous-entend une forte réduction de la durée d’indisponibilité, ce qui passe par des solutions de réplication en temps réel entre différents serveurs situés sur un même site ou sur des sites géographiques différents. Un plan de reprise d’activité (PRA) consiste à définir les procédures de retour à une situation acceptable en cas d’incident plus ou moins important sur un serveur, un ensemble matériel, voire un site géographique complet. Ces deux aspects sont complémentaires et le plus important dans tous les cas consiste à définir des procédures en cas d’incident. Ces procédures seront validées, jouées régulièrement et mises à jour en fonction des évolutions des plateformes ainsi que les évolutions des scénarios d’incident. Dans ce dossier, nous allons voir quelles sont les différentes solutions de base qui peuvent être mises en oeuvre dans ces processus de continuité et de reprise d’activité.
| Contenu complémentaire : - Groupe utilisateur Exchange : http://msexchange.fr/ - Article de Pascal Creusot : La haute disponibilité au niveau de la messagerie Exchange |
Lire l'article
La haute disponibilité à votre portée dans Exchange 2007
Exchange Server 2007, vous pouvez trouver des solutions qui ne vont pas « faire exploser » votre budget et n’exigeront pas de votre équipe Exchange qu’elle passe un doctorat en clustering. Nous allons commencer ici notre examen des solutions de haute disponibilité d’Exchange 2007 par une présentation générale. Dans les prochains articles, nous explorerons plus en détail ce sujet avec la configuration de la réplication locale en continu (LCR) et de la réplication continue en cluster (CCR) dans Exchange 2007.
Lire l'article
Exchange 2007 Database Troubleshooter
En novembre 2005, Microsoft a lancé un outil gratuit remarquable et cet événement est probablement passé inaperçu de la majorité des administrateurs. Dénommé à l’origine ExDRA (Exchange Disaster Recovery Analyzer), cet outil avait pour objectif de simplifier la Microsoft Exchange Server 2007 en décembre 2006, ExDRA n’est plus disponible sous forme d’outil téléchargeable séparément ; en fait, le nouvel outil de dépannage de base de données est intégré à l’Assistant Dépannage Microsoft Exchange (ExTrA, Exchange Troubleshooting Assistant), lequel est inclus dans Exchange Management Console (EMC). Il est possible d’utiliser ExTrA pour dépanner des bases de données Exchange 2000 Service Pack 3 (SP3) ou ultérieur.
Notez que si vous disposez encore d’une copie d’ExDRA, vous pouvez continuer à l’utiliser sur les bases de données Exchange 2000 SP3 ou ultérieur. Avec son interface et son approche basées sur l’infrastructure ExBPA (Exchange Best Practices Analyzer) bien connue, l’outil de dépannage de base de données (Database Troubleshooter) analyse une base de données de boîtes aux lettres ou de dossiers publics Exchange et tous les fichiers journaux des transactions associés disponibles, afin de fournir des indications sur la faisabilité d’une récupération et des recommandations.
Les administrateurs Exchange confrontés à des incidents de montage de base de données évaluent fréquemment de manière incorrecte le problème en cours. Ils exécutent souvent sans nécessité Eseutil ou Isinteg, d’où des périodes d’indisponibilité longues et inutiles du système de messagerie. Le Database Troubleshooter a pour but de démystifier la récupérabilité au niveau base de données Exchange, afin que vous puissiez prendre des décisions de récupération avisées, sans tâtonner au moyen de l’approche essai / erreur.
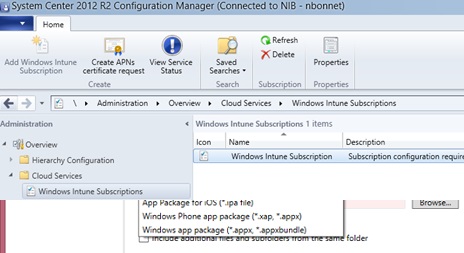
Permettez à votre System i d’appeler chez vous sur le Web
IBM a ajouté des commandes de service à distance en V5R1 et amorcé ainsi un virage important dans la maintenabilité du logiciel système du System i. En déplaçant les communications d’assistance des liens SNA spécialisés vers la connectivité TCP/IP dial-up – même via modem – IBM a donné beaucoup plus de facilités aux utilisateurs de son assistance à distance.Au début, IBM distribuait les commandes de service via son processus PTF ; mais avec la V5R3, les commandes CL de service étaient livrées avec i5/OS. Cette release a aussi ajouté la connectivité directe par Internet : pour le bonheur des utilisateurs qui pouvaient dès lors bénéficier de la large bande d’Internet pour télécharger les PTF et pour soumettre de grands fichiers de compte-rendu de problèmes. IBM a par la suite octroyé cette possibilité aux releases i5/OS antérieures via des PTF. (Pour un bref aperçu des commandes de service i5/OS du passé au présent, voir « A Short History of i5/OS Service Commands » www.itpro.fr Club Abonnés.)
Lire l'article
Journal à distance
Dans les entrailles d’i5/OS se cache une technologie qui commence à susciter de l’intérêt. A en croire le volume de questions posées au lab Rochester d’IBM sur ce thème, on mesure une extrême sensibilisation au cours de la dernière année. Il s’agit du journal à distance, un petit aspect du support peu connu jusque-là.
Introduit voilà quelques années, le journal à distance est passé presque inaperçu pendant un certain temps. Mais, récemment, les projecteurs se sont braqués sur lui et il est le moyen privilégié de transporter efficacement les changements de données récents d’un iSeries sur un autre.Mon premier contact avec le journal à distance remonte à quelques années, quand la V4R2 de l’OS/400 était encore en chantier.
On m’a invité alors à rejoindre l’équipe de développement du journal IBM, à participer à la conception du journal à distance, et à l’amener sur le marché. Mes prédécesseurs d’alors voyaient le journal à distance comme un simple mécanisme de transport amélioré et très efficace grâce auquel nos Business Partners haute disponibilité pourraient construire les versions améliorées de leurs produits.
Ils n’ont pas pressenti que d’autres fournisseurs le considèreraient comme un moyen facile d’atteindre le marché de la haute disponibilité. Et peu d’entre eux ont perçu que ce serait aussi un moyen intéressant d’établir un environnement coffre-fort à distance. Pendant un temps, nous avons simplement cru fabriquer une meilleure tuyauterie pour les produits existants.

De la haute disponibilité à la continuité de l’activité
Les notions de haute disponibilité, et de poursuite de l’activité sont intimement liées à la reprise après sinistre. Et, trop souvent, nous nous trouvons au coeur même de la catastrophe. Les ouragans Katrina et Rita ont dévasté des centaines de milliers de kilomètres carrés, déplacé des milliers de personnes et perturbé une multitude de sociétés et d’entreprises. Ailleurs dans le monde, d’autres catastrophes naturelles ont anéanti des populations entières. L’enseignement à en tirer n’est pas simplement que la nature a le pouvoir de mettre fin à nos vies et à nos activités, mais aussi l’étendue et la durée de telles tragédies. Trop souvent, nous considérons les sinistres comme des ennuis qui suspendent notre exploitation pendant une courte période. En réalité, nous voyons de grandes zones géographiques frappées pendant plusieurs mois.La nature n’est pas le seul danger que courent les entreprises. Il y a aussi les menaces de terrorisme, comme en témoignent les attaques mortelles dans le monde et près de chez nous. Une sale bombe ou un agent biologique peut rendre une ville inhabitable pendant plusieurs années. Songez aux centaines ou aux milliers d’ordinateurs présents à proximité de la Maison Blanche et du Capitole. Ces centres de gouvernement sont-ils suffisamment protégés contre d’éventuelles campagnes de terreur ?
La figure 1 ne contient qu’une liste partielle des sinistres susceptibles de frapper une société. Si de tels événements se produisent, nous risquons d’être coupés de nos centres informatiques pendant de longues périodes. Et même si nous pouvons récupérer l’information depuis des sites de secours, le personnel pourrait être tellement dispersé que toute reprise de l’exploitation normale serait impossible. Pis encore, nos centres de secours pourraient se trouver près de l’entreprise et, par conséquent, être aussi mal en point que le site principal. Enfin, même si la reprise purement informatique réussit, nos autres actifs et ressources pourraient être tellement affectés que toute poursuite de l’activité serait illusoire.
En tant que professionnels IT, nous devons, avec nos entreprises, élaborer des plans à plusieurs niveaux pour la haute disponibilité, la poursuite de l’exploitation, la reprise après sinistre et la continuité de l’activité. De tels plans doivent viser une protection continue contre des dangers très divers, allant de problèmes techniques internes aux événements externes et aux perturbations globales. Ils doivent répondre aux préoccupations de tous les responsables de l’entreprise, dans tous les services et départements.
Serveurs tolérants aux pannes
par Mark Weitz - Mis en ligne le 26/11/2003
La meilleure solution haute disponibilité ?
L'une des responsabilités d'un service
informatique est d'éviter toute interruption
des applications critiques.
Bien que les produits en cluster offrent
la haute disponibilité, le processus de
failover peut perturber le traitement
de l'application pendant 30 secondes
ou plus. Selon le modèle de l'application
client, les utilisateurs peuvent être
obligés de se reconnecter à l'application
en cluster quand elle reprend sur
le nouveau noeud...
L'une des responsabilités d'un service
informatique est d'éviter toute interruption
des applications critiques.
Bien que les produits en cluster offrent
la haute disponibilité, le processus de
failover peut perturber le traitement
de l'application pendant 30 secondes
ou plus. Selon le modèle de l'application
client, les utilisateurs peuvent être
obligés de se reconnecter à l'application
en cluster quand elle reprend sur
le nouveau noeud, et si le noeud défaillant
se trouve sur un système distant,
il faudra dépêcher un technicien
pour le réparer. De plus, les clusters
basés sur Windows 2000 Datacenter
Server exigent une administration très poussée pour garder leur haut niveau
de disponibilité.
Pour répondre à certaines de ces
préoccupations, plusieurs fournisseurs
de serveurs ont mis au point des produits
spécialisés. Marathon, NEC et
Stratus ont présenté des solutions qui
prétendent offrir une fiabilité matérielle
de 99,99 % aux départements et
aux entreprises petites et moyennes.
Leurs solutions s'appuient davantage
sur la tolérance aux pannes que sur le
clustering et elles utilisent Win2K
Advanced Server avec les versions
standard de vos applications. Contrairement
au clustering, où une
défaillance du serveur arrête temporairement
les applications tandis que le
traitement de l'application se déplace
sur un autre noeud, les systèmes tolérants
aux pannes permettent aux applications
de fonctionner sans interruption
sur un sous-système redondant.
Une fois les parties défaillantes remplacées,
les noeuds en cluster et les systèmes
tolérants aux pannes arrêtent
temporairement le traitement. NEC et
Stratus déclarent que la mise sous tension
et la resynchronisation de la nouvelle
partie (appelée réintégration
dans les systèmes tolérants aux
pannes) peut demander jusqu'à 12
secondes sous Win2K AS. Marathon
déclare que ces temps de réintégrationsont de quelques secondes au plus. Par
comparaison, la remise sur pied d'un
cluster peut arrêter le traitement de
l'application pendant 30 secondes ou
plus.
Quand on compare le clustering et
la tolérance aux pannes, il faut se souvenir
que le service Microsoft Cluster
traite des défaillances matérielles et logicielles,
tandis que les systèmes tolérants
aux pannes s'intéressent principalement
à la fiabilité du matériel. Bien
que les techniques utilisées par NEC,
Marathon et Stratus dans leurs architectures
tolérantes aux pannes réduisent
la probabilité d'une défaillance logicielle,
s'il vous faut le haut niveau de
fiabilité logicielle des services en cluster,
vous devrez acheter des versions
orientées cluster de vos applications,
ce qui constituera une dépense supplémentaire.

Mise en oeuvre de Websphere Application Server
Depuis quelques mois, la communauté informatique semble s'être installée dans l'ère de l'architecture "trois-tiers". Un monde nouveau se prépare à accueillir nos futurs développements. Toutefois, avant de mettre en oeuvre nos prochains programmes, il va nous falloir explorer ce nouvel univers, en découvrir la géographie, en suivre les chemins, en visiter les arcanes, en éviter les pièges ...
L'AS400 peut héberger ce nouveau monde.
Fort de ce postulat, nous nous sommes fixés cette tâche "simple" : "Mettre en oeuvre sur AS400 l'environnement nécessaire et suffisant à l'hébergement et à l'exécution de notre premier programme "trois-tiers", ou "Comment mettre en oeuvre l'exhaustivité des composants permettant d'exécuter notre premier programme "trois-tiers".
L'article qui suit vise à présenter de bout en bout la mise en oeuvre d'un serveur Websphere sur AS400, ainsi que d'une application Web, en s'attachant à utiliser les logiciels disponibles sur la machine, donc sans surcoût ni utilisation de composants "exotiques".
Toutes les références produits, niveaux de version et groupes de PTF citées sont pour la V5R1 de l’OS400. La démarche, elle, est la même et fonctionne tout à fait en V4R5 (voir l’encadré Les Bonnes Adresses)
Lire l'article
Stratus Technologies démocratise la tolérance de panne
Nouvelle gamme de systèmes ftServer, politique de partenariat très active, segments de marchés bien identifiés : Stratus Technologies prouve, grâce au support optimisé de Windows 2000, que ses plates-formes à tolérance de pannes sont non seulement plus fiables que les clusters, mais surtout adaptées à un plus grand nombre d’applications critiques.
Lire l'article
Evitez les interruptions avec Performance Navigator
La plupart des entreprises sont confrontées à une constante demande croissante de ressources système. L’ensemble de ces transactions, bases de données, applications, et enregistrements système doivent être traités et stockés quelque part. Trop souvent, le service informatique perd une guerre d’usure, au fur et à mesure que les ressources système sont engagées lentement mais sûrement.Sur le marché iSeries, il existe une palette d’outils de gestion de performances, de planification de capacité, et de détermination de problèmes, qui aident les administrateurs à détecter les goulets d’étranglement de performance, régler les systèmes, réguler l’utilisation excessive du stockage sur disque, et planifier d’éventuelles mises à niveau. Il est un produit qui fournit de l’aide dans tous ces domaines à la fois: Performance Navigator de Midrange Performance Group.
Lire l'articleLes plus consultés sur iTPro.fr
- Reporting RSE : un levier d’innovation !
- De la 5G à la 6G : la France se positionne pour dominer les réseaux du futur
- Datanexions, acteur clé de la transformation numérique data-centric
- Les PME attendent un meilleur accès aux données d’émissions de la part des fournisseurs
- Fraude & IA : Dr Jekyll vs. Mr Hyde, qui l’emporte ?
