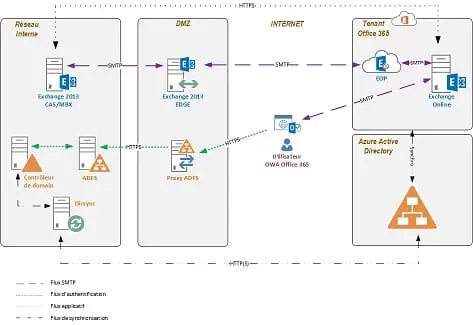
Reporting Services : Qu’en est-il des services Web ?
Vous vous interrogez peut-être sur les alternatives permettant de proposer l’authentification Windows.Une approche fiable consiste à employer le service Web Report Server.
Lire l'article
Utilisation de Reporting Services dans un environnement Internet / Extranet
Il y a quelques mois, j’ai travaillé avec un client qui déployait une nouvelle version d’un portail Web de commerce électronique. L’application, utilisée principalement par les partenaires du client, expose les données de ventes et d’autres informations confidentielles. Le client souhaitait employer des applications sur Internet ou des extranet, cet article explique comment déployer d’abord un modèle d’authentification personnalisé pour Reporting Services, puis comment développer des rapports capables, au moment de l’exécution, de filtrer les données selon l’utilisateur qui consulte les rapports. Vous pouvez également vous servir de cette technique de filtrage avec le modèle de sécurité par défaut de Reporting Services.
Lire l'article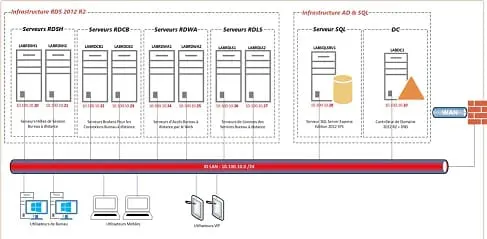
Reporting Services : Conseils et astuces
Le choix et l’installation de SQL Server Reporting Services (SSRS) constituent uniquement la première étape visant à satisfaire la multitude des consommateurs de rapports présents dans votre entreprise. Il vous reste maintenant à produire des rapports éblouissants qui tirent parti des fonctionnalités avancées, afin d’afficher les données conformément à la myriade d’attentes des utilisateurs, sans pour autant délaisser vos autres tâches.
Cet article propose quelques conseils et astuces pour créer des rapports à la fois utiles et souples, qui s’exécutent de manière appropriée. Il indique également un échantillon d’outils tierce partie qui vous permettront d’étendre les fonctionnalités de SSRS.

Un outil de reporting fort à propos
Depuis le lancement initial de .NET Framework 2.0.
Lire l'article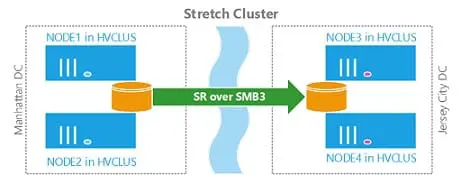
Optimisation des bases de données SQL Server : l’exploitation
Votre modèle des données est parfait : justement normalisé et très légèrement dénormalisé par des techniques fiables et pour des données dont il est prouvé que cela apporte un gain significatif. Vos requêtes sont optimisées et les serveurs, tant logiques que physiques, comme leurs environnements sont taillés, dimensionnés, mesurés, configurés pour le volume de données et de transactions à subir. Enfin, vous avez pensé au découpage de vos espaces de stockage, choisi vos disques et constitué vos agrégats en conséquence… Pourtant il vous manque une brique pour parfaire votre oeuvre : penser l'exploitation de vos données au quotidien, c'est là SQL Server sur le site communautaire de developpez.com, un internaute postait un remarquable message. Il avait une procédure complexe longue et coûteuse en traitement qui importait des données dans une base, avec une planification quotidienne de nuit. Un matin quelle ne fût pas sa stupeur de constater que cette procédure qui durait habituellement un peu plus d'une heure, n'était pas encore terminée. Il attendit donc la fin du traitement et constata que ce dernier avait mis près de 10 heures, soit 8 fois plus qu'ordinairement. Que s'était-il passé ?
| Contenu complémentaire Numéro hors série : Gestion et optimisation des environnements multi bases de données Le site du groupe utilisateurs de SQL Server : le GusS |
Lire l'article

Prenez le contrôle de vos rapports avec ReportViewer
Visual Studio 2005 constitue la clé de voûte de toutes ces fonctionnalités. Il s’agit d’un outil souple, utilisable dans les Windows Forms et formulaires Web pour afficher deux types de rapports. Le premier type est un rapport côté serveur, qui nécessite un serveur de rapports SSRS.
Ce dernier fournit les valeurs des paramètres du rapport, crée les datasets et assure le rendu. Le contrôle ReportViewer affiche ensuite le rapport rendu dans une fenêtre d’application. Lorsque vous créez des rapports côté serveur, vous utilisez le mode de traitement distant. Le deuxième type est un rapport local. Ces rapports sont distribués en tant que partie intégrante d’une application et ne requièrent pas de serveur SSRS. Toutefois, le fait de s’affranchir du lien à un serveur de rapports a un coût. L’application doit fournir les valeurs pour les paramètres du rapport et créer tous les datasets. Le contrôle ReportViewer assure le rendu du rapport. Lorsque vous optez pour cette approche, vous utilisez le mode de traitement local.
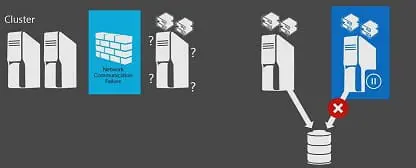
Sécurité SQL
IBM a intégré en douceur la sécurité SQL à la panoplie de sécurité System i existante. Ces fonctions SQL ne se contentent pas d’imiter les mesures de sécurité existantes : elles les étendent et les renforcent. SQL connaît une rapide croissance et devient un langage de plus en plus incontournable pour tous les développeurs System i. Cet article actualise vos connaissances en sécurité SQL.
La sécurité SQL repose sur deux piliers : les deux instructions GRANT et REVOKE. En termes très simples, ces instructions SQL correspondent aux commandes CL Grant Object Authority (GRTOBJAUT) et Revoke Object Authority (RVKOBJAUT). Quand vous exécutez une instruction SQL GRANT ou REVOKE, vous utilisez des mots-clés pour octroyer ou révoquer des privilèges à un objet SQL. Sous le capot, le fait d’octroyer des privilèges SQL revient à octroyer une ou plusieurs autorités i5/OS à un ou plusieurs objets i5/OS.
| Contenu complémentaire : Automatisez vos audits de sécurité Construisez vos propres systèmes de sécurité automatisés Sécuriser votre base de données avec le point de sortie Open Database File |
Lire l'article

Construisez un système ETL simple avec SSIS
Vous savez probablement que vous pouvez utiliserun entrepôt de données (data warehouse).Mais comment allez-vous procéder ? À quoi ressemble une application ETL ?SSIS se targue de proposer tellement de nouveautés que les nouveaux venus ont l’impression d’avoir déballé un puzzle sur leur bureau. Il est difficile d’assembler les pièces sans avoir sous les yeux une vue d’ensemble du résultat final, notamment lorsque les pièces d’autres puzzles viennent jouer les trouble-fêtes ou lorsque certains éléments manquent !
L’objectif de cet article est justement de fournir la vue d’ensemble nécessaire : nous allons aborder les opérations élémentaires de conception et de construction de packages SSIS, et ainsi fournir les bases pour l’étude ultérieure des techniques de chargement incrémentiel concernant les dimensions et faits, ainsi que les variables, les scripts et l’audit de base des processus.
Les compléments d’exploration de données SQL Server 2005 pour Office 2007
De nombreux outils d’analyse s’intègrent à SQL Server 2005 offrent des fonctionnalités puissantes pour l’analyse des données, mais c’est seulement depuis peu que Microsoft propose des outils standard pour apporter les possibilités du data mining sur le poste de travail.En février 2007, l’éditeur de Redmond a lancé les compléments d’exploration de données pour Office 2007. Ceux-ci permettent d’exploiter les fonctions d’analyse prédictive de SQL Server 2005 dans Excel 2007 et Microsoft Office Visio 2007. Dans cet article, nous allons examiner l’installation et la configuration de ces compléments et développer un exemple complet. Nous nous attarderons plus spécifiquement sur l’un des outils complémentaires, à savoir le client d’exploration de données pour Excel (Data Mining Client for Excel).
| Contenu complémentaire : - Développez votre connaissance de l'analyse décisionnelle - Data Mining Reloaded |

Placez les données de vos cubes sur le devant de la scène
une autre perspective de leurs données. Cette capacité peut s’avérer importante lorsque les rapports doivent afficher un grand nombre de mesures et se servent des dimensions en tant que tranches de données.
Par exemple, un rapport qui présente plusieurs mesures pour un seul employé ou produit n’a pas besoin de reprendre cette même information sur les lignes ou dans les colonnes. Par conséquent, nous allons voir comment placer les mesures sur les lignes et une autre dimension, Time, dans les colonnes, tout en réalisant les tranches à partir d’une autre dimension. Nous allons également expliquer comment paramétrer une requête MDX et appliquer un formatage aux valeurs.

Guide pour traiter les erreurs de SQL imbriqué
Dès lors que SQL se généralise dans les applications de production, il importe de bien vérifier et traiter les erreurs des instructions SQL imbriquées. Quand vous codez des instructions SQL imbriquées dans un langage évolué, tel que ILE RPG ou ILE Cobol, vous devez toujours vérifier la bonne fin de chaque instruction SQL exécutable, puis traiter comme il se doit les éventuelles conditions inattendues. Cet article fournit quelques conseils, techniques et profils de coding qui facilitent considérablement cette tâche.
En matière de programmation SQL imbriquée, il faut observer une règle simple : vérifier la valeur SQL state aussitôt après chaque instruction SQL exécutable du programme. Quand le SQL runtime revient à votre programme après avoir tenté d’exécuter une instruction SQL, le runtime définit une variable de programme nommée SQLState pour la valeur SQL state. (Les instructions déclaratives imbriquées, telles que Declare Cursor, et les directives de précompilateur, telles que Set Option, ne sont pas exécutées par le SQL runtime, et donc elles ne contribuent jamais à définir SQL state.)
SQL state est un code de cinq caractères présentant la structure suivante : XXYYY, où
• XX désigne la classe
• YYY désigne la sous-classe
Les significations des valeurs classe sont les suivantes :
• 00 – instruction correctement exécutée sans condition
• 01 – instruction correctement exécutée avec avertissement
• 02 – l’instruction n’a traité aucune donnée
• 03 à ZZ – l’instruction a échoué à cause d’une erreur
A propos de ces classes, on peut noter plusieurs choses. La classe « 00 » ne contient que la valeur SQL state « 00000 », donc on peut tester la chaîne entière plutôt que la seule classe.
Pour plusieurs des valeurs SQL state dans la classe « 01 », divers avertissements et erreurs column-level peuvent être indiqués par une valeur positive dans la variable d’indicateur null associée à une variable hôte. Les erreurs column-level potentielles incluent la troncature de chaîne et de date heure, les erreurs arithmétiques, les erreurs de conversion de caractères et les erreurs de mapping de données. Le sujet « References to host variable » du manuel SQL Reference fournit une description complète des paramètres de variables indicateurs. S’agissant de conditions spécifiques aux colonnes, il faut coder les tests pour qu’ils conviennent à l’application en plus de la vérification d’erreurs au niveau instruction montrée dans cet article.
La classe « 02 » inclut le SQL state « 02000 », lequel indique généralement que (1) aucune ligne n’a été renvoyée sur une opération d’entrée, (2) aucune ligne n’a été ajoutée par une opération Insert qui utilise un subselect pour spécifier de nouvelles lignes, ou (3) aucune ligne n’a satisfait à la condition de recherche d’une instruction Update ou Delete. Que l’une de ces conditions soit une erreur ou une condition escomptée, dépend de l’application ; c’est un aspect que votre code de vérification d’erreurs devrait prendre en considération.
La figure 1 fournit une liste complète des valeurs de classe. Le dernier manuel V5 SQL Messages and Codes fournit une liste complète des valeurs SQL state. Ces valeurs se veulent homogènes dans toute la famille IBM DB2 et sont fondées sur le standard SQL 1999. Pour plus d’informations à ce sujet, voir l’encadré « Où trouver des valeurs SqlState et SqlCode ».
| Contenu complémentaire : --> Lire l'article 
Le service notificationAvec le service de notification, base de données, ou bien dans un deuxième temps en utilisant l’ajout/suppression de programme du panneau de configuration. Lire l'article
Optimisation des bases de données MS SQL Server – Partie 2Seconde partie : le serveur - ressources physiques, ressources logiquesJe pose souvent la question en ces termes lors des formations que je donne : parmi les différentes formes d’informatique, laquelle nécessite les machines ayant les plus grandes ressources ? La plupart du temps, les étudiants et les stagiaires m’affirment que c’est l’informatique scientifique, gavée des exploits des antiques Cray et de Deep Blue et des monstres utilisés pour les calculs de la météo. D’autres pensent que ce sont les machines de la conquête spatiale… Peu savent que l’on trouve les systèmes les plus étoffés dans l’informatique de gestion. Un système comme SABRE de United Airlines fut longtemps l’un des systèmes de gestion de bases de données les plus énormes qui soit. 
Deux outils pour une optimisation permanente de SQL ServerDepuis des années, le support technique de Microsoft (PSS) se sert de deux outils, OSTRESS et Read80Trace, afin de simuler des scénarios et d’analyser des fichiers de trace SQL Server pour le compte de ses clients. Au cours de l’édition 2004 de la conférence PASS (Professional Association for SQL Server), ces outils ont été dévoilés au public.Les DBA et développeurs SQL Server verront dans OSTRESS un outil appréciable pour la mise en oeuvre de scénarios de test de charge complexes et Read80Trace les aidera à analyser des fichiers de trace SQL Server afin de résoudre des problèmes de performances. Cet article propose quelques scénarios d’utilisation détaillés pour ces outils et fournit des indications afin de les mettre en oeuvre efficacement. 
Réplication de base de données contre réplication du stockageDe nombreux base de données permet de satisfaire des exigences de réplication spécifiques non prises en charge par l’autre approche. Le présent article se propose d’examiner les trois facteurs décisifs à prendre en considération afin de combiner au mieux les deux approches pour votre organisation. Lire l'article
De la valeur de l’intégration SQL Server 2005 et Visual Studio 2005Paul Flessner et S. Somasegar, vice-présidents chez Microsoft, parlent à coeur ouvert de l’approche « Une équipe qui gagne »Au cours d’un entretien, les vice-présidents de Microsoft Paul Flessner (vice-président directeur de la division des applications serveur, laquelle inclut https://www.itpro.fr Club abonnés.) Lire l'article
Optimisation des bases de données MS SQL Server – Partie 1On a beau répéter que l'optimisation de bases de données ne relève pas d'outils ni d'automatismes, mais du simple artisanat, il y a toujours quelques personnages pour prétendre qu'il suffit de faire ceci ou cela, pour obtenir de bonnes performances. Si les choses sont plus complexes qu'il n'y paraît, il n'en reste pas moins vrai que certains principes simples et des règles d'une grande évidence qui devraient guider l'équipe en charge du développement d'un projet informatique, sont souvent ignorées voire sciemment bafouées. 
Développez votre connaissance de l’analyse décisionnelleJe dois admettre un fait. Je faisais partie des personnes du monde des bases de données relationnelles qui ne s’intéressaient pas réellement à Analysis Services. Je pensais qu’un cube OLAP était le poste où travaillait un certain Oliver Lap du département de la comptabilité entre 8 h 00 et 17 h 00. Pour moi, les dimensions étaient réservées aux physiciens et aux adeptes de la série La quatrième dimension.Mon point de vue s’est modifié il y a quelques années, lorsque j’ai appris en quoi Analysis Services pouvait être avantageux, pour moi comme pour mes clients. Si vous vous focalisez depuis toujours sur les bases de données relationnelles, vous allez peut-être changer d’avis en essayant la CTP (Community Technical Preview) analyse décisionnelle (en anglais BI (Business Intelligence)) fantastiques proposées par SSIS (SQL Server Integration Services) pour vos applications relationnelles. Deux nouvelles tâches de transformation vous simplifieront la vie lorsque vous travaillez sur des données incohérentes et une tâche de data mining vous permettra de créer un modèle de données s’adaptant aux évolutions de l’activité. 
ASP.NET 2.0 : Investissez dans les performancesQue vous soyez un développeur ASP.NET qui travaille sur des applications orientées données ou un DBA SQL Server gérant des applications ASP.NET, vous allez probablement découvrir que certaines possibilités d’ASP.NET 2.0 peuvent vous aider à « booster » les performances de votre site Web. Avec SQL Server afin d’invalider automatiquement les données mises en cache qui sont utilisées par le serveur Web. Lire l'article
Interviews des chefs de produits MicrosoftDécouvrez en exclusivité l’interview d’Alain Le Hégrat, chef de produit Windows Server, qui revient sur la sortie de SQL Server 2008. Lire l'articleLes plus consultés sur iTPro.fr
À la une de la chaîne Data
X
Gérer le consentement aux cookies
Fonctionnel Toujours activé
Le stockage ou l’accès technique est strictement nécessaire dans la finalité d’intérêt légitime de permettre l’utilisation d’un service spécifique explicitement demandé par l’abonné ou l’internaute, ou dans le seul but d’effectuer la transmission d’une communication sur un réseau de communications électroniques.
Préférences
Le stockage ou l’accès technique est nécessaire dans la finalité d’intérêt légitime de stocker des préférences qui ne sont pas demandées par l’abonné ou la personne utilisant le service.
Statistiques
Le stockage ou l’accès technique qui est utilisé exclusivement à des fins statistiques.
Le stockage ou l’accès technique qui est utilisé exclusivement dans des finalités statistiques anonymes. En l’absence d’une assignation à comparaître, d’une conformité volontaire de la part de votre fournisseur d’accès à internet ou d’enregistrements supplémentaires provenant d’une tierce partie, les informations stockées ou extraites à cette seule fin ne peuvent généralement pas être utilisées pour vous identifier.
Marketing
Le stockage ou l’accès technique est nécessaire pour créer des profils d’internautes afin d’envoyer des publicités, ou pour suivre l’internaute sur un site web ou sur plusieurs sites web ayant des finalités marketing similaires.
|