Les termes qui définissent le mieux un Cloud sont nombreux. Les deux premiers que je cite lorsque je dois présenter ces avantages sont l’élasticité et le paiement à l’utilisation, qui sont très liés dans certains scénarios.
Mise à l’échelle vs Metrics

Ne payer que ce que l’on utilise, seulement lorsque l’on doit l’utiliser. Le lien est facile à faire avec les services de mise à l’échelle proposés sur Azure. Ce que l’on retrouve dans les groupes de machines virtuelles identiques avec équilibrage de charge et le scaling automatique des ressources. Le scaling (mise à l’échelle) est la capacité à provisionner / dé-provisioner de la puissance de calcul de façon automatique.
Il existe pour ce besoin deux types de mise à l’échelle :
- Verticale
Une modification de taille verticale est une solution à réserver aux seules applications qui ne supporteraient pas la répartition sur plusieurs machines. Cette mise à l’échelle est possible mais présente quelques inconvénients : une rupture de service le temps de la mise à l’échelle et une limite de taille qui sera forcément atteinte à un moment ou un autre, une seule machine physique a quand même des limites matériels …
- Horizontale
Ici, la souplesse et l’élasticité sont obtenues par l’ajout ou le retrait de ressources. Le modèle de machines virtuelles ne change pas, mais une ou plusieurs machines de taille identique (on parle d’instance) sont ajoutées et retirées au besoin. Le terme identique est important, le provisionnement se fait sur une machine équivalente en termes de matériel, mais également de logiciel. Ce point ne sera pas détaillé dans cet article, mais, en cas de besoin, la machine virtuelle qui démarre pour venir consolider la puissance de calcul doit être pourvue des mêmes fonctionnalités.
Eléments de décision
Les Métriques sont essentiels pour décider de la manière dont doit être pilotée l’élasticité. Ce sont des compteurs de performances, la vue est centralisée sur le menu de la ressource. Par exemple, une machine virtuelle ou une base de données SQL Server managée (PAAS). La vue est consolidée pour plusieurs compteurs, et les données sont affichées sur une durée allant de 1 heure à 30 jours. Suffisant dans la majorité des cas.
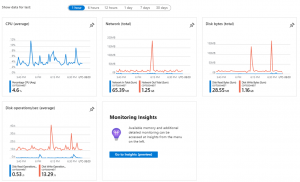
Métriques d’une VM, durée 1 heure, image éditeur
Le point de départ à toute analyse est une simple observation visuelle des compteurs. Si possible, cette action est menée sur les applications majeures de l’entreprise, au plus tôt. C’est-à-dire avant même que les utilisateurs remontent des dysfonctionnements. Évident ? Oui… mais pas toujours fait dans cet ordre.
Une fois cette première analyse rapide terminée, chaque compteur peut être isolé puis les données sont affinées en zoomant « à la souris » sur les pics de consommation. Simple et efficace. Il est également possible de jouer avec le type de compteur pour une même vue. Par exemple, la consommation moyenne pour le processeur est analysée différemment de la consommation instantanée. Tous ces paramètres sont facilement modifiables dans l’interface graphique.
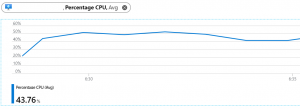
Zoom pour une analyse fine, durée 5 mn (le nom de la ressource est volontairement supprimé dans cette vue)
Attention, cette phase d’analyse est importante et prend beaucoup de temps ! Un bon fonctionnement de son infrastructure Cloud est assuré seulement si cette infrastructure est bien préparée ! Voir à ce sujet l’article « La IaaS Azure n’est pas le Cloud, c’est un Datacenter »
De cette analyse, sont tirés les 3 enseignements principaux. Pourquoi 3 ?
Parce que bien souvent, ces analyses, avant même de donner le départ aux actions de mise à l’échelle permettent de corriger quelques mauvaises répartitions des ressources déjà en place. Une machine à 5 % de CPU moyen sur les 30 derniers jours n’est-elle pas sur taillée par exemple ?
Puis les Métriques sont ensuite séparés en deux parties :
– Ils présentent un cycle régulier de surcharge. Les besoins en ressources sont régulièrement élevés lors d’une même période dans le mois, tous les mardis soir de 18 h à 22 h. Il y a pendant cette courte période une montée rapide des besoins en ressources, c’est un pic d’activité récurrent.
– Le cycle n’est pas régulier, les montées en charge sont plus douces, il est difficile de dégager une récurrence dans les montées en charge.
Cette logique de classification est également adaptée lorsque les besoins sont moins importants et qu’il faut prévoir un retrait de ressources.
L’analyse et la classification sont terminées, il faut maintenant mettre à l’échelle …
Téléchargez cette ressource

Rapport mondial 2025 sur la réponse à incident
Dans ce nouveau rapport, les experts de Palo Alto Networks, Unit 42 livrent la synthèse des attaques ayant le plus impacté l'activité des entreprises au niveau mondial. Quel est visage actuel de la réponse aux incidents ? Quelles sont les tendances majeures qui redessinent le champ des menaces ? Quels sont les défis auxquels doivent faire face les entreprises ? Découvrez les top priorités des équipes de sécurité en 2025.
Mise à l’échelle
Dans cet exemple, la mise à l’échelle concerne un ensemble de machines virtuelles. Azure propose d’autres ressources sur ce même sujet (App services, Kubernetes …Etc). La mise à l’échelle est une option de départ lors de la création d’un groupe de machines virtuelles.
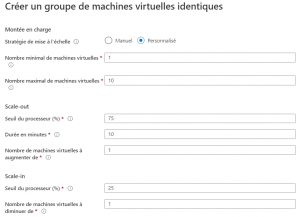
Mise à l’échelle personnalisée lors de la création du groupe depuis un métrique (seuil processeur)
Mais ces options sont également possibles post création.
Dans le menu du groupe de machines itproscaleset, une option Montée en charge est disponible. On retrouve sur cet écran 2 types de mise à l’échelle :
- Manuel
C’est un ajout d’une ou plusieurs machines identiques déclenché depuis le portail directement par l’opérateur. Un scénario courant pour ce mode de fonctionnement et un test de charge sur l’environnement.
- Automatique
Qui est normalement le type le plus utilisé en production. Cette famille est proposée sous plusieurs formes très différentes selon les cycles définis dans le chapitre Eléments de décision.
1 / Le cycle n’est pas régulier, les montées en charge sont « douces », le modèle à base de métriques est adapté. Ici, les règles de montées en charge sont définies selon plusieurs conditions. CPU ou Disk Write et les limites d’instance sont positionnées.
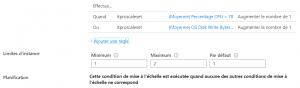
Mise à l’échelle pour des métriques CPU et Disk
2 / Le cycle est régulier et récurrent, les montées en charges sont importantes. Il n’y a pas besoin de métriques pour ce genre de cas, la situation est connue « à l’avance ». Il y a besoin de provisionner 3 instances de machines virtuelles supplémentaires tous les lundis entre 6 h et 18 h. La mise à l’échelle est planifiée et l’ajout / suppression de ressources se fait selon un calendrier bien défini.
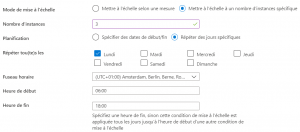
Mise à l’échelle selon un calendrier
Ces deux scénarios sont les plus courants mais ce ne sont pas les seuls. Avec une bonne connaissance de ses récurrences et de ses métriques, il est possible de travailler encore plus finement les ajouts / retraits de ressources. En cumulant par exemple un calendrier et des règles de déclenchement.
Tous les lundis, ce ne sont pas 3 instances qui sont automatiquement ajoutées, mais elles ne le sont que si les règles CPU sont atteintes.
C’est un peu le meilleur des 2 mondes. Il y aurait encore beaucoup à dire sur le sujet. Les règles sont plus fines à régler que ce que présente ce sujet. Attention par exemple à ne pas rendre trop agressives les règles de démarrage des instances. Démarrer une instance trop rapidement peut parfois être contre-productif. Le pic est tellement court que l’instance n’est pas encore provisionnée et le besoin n’est plus présent.
La mise à l’échelle est un beau sujet, mais c’est également un sujet très fin qui apportera beaucoup en termes de disponibilité et d’économie sur votre Cloud Azure.
Pour résumer, voici un bon point de départ en 3 étapes :
1 / Utiliser les métriques pour décider de ce qui demande une adaptation des ressources.
2 / Choisir le mode le plus adapté qu’il soit manuel depuis un calendrier, automatique depuis des métriques ou que ce soit un mélange de ces 2 solutions.
3 / Revenir régulièrement sur les valeurs de métriques pour revalider les mesures.
Les articles les plus consultés
A travers cette chaîne
A travers ITPro
Les plus consultés sur iTPro.fr
- De la 5G à la 6G : la France se positionne pour dominer les réseaux du futur
- Datanexions, acteur clé de la transformation numérique data-centric
- Les PME attendent un meilleur accès aux données d’émissions de la part des fournisseurs
- Fraude & IA : Dr Jekyll vs. Mr Hyde, qui l’emporte ?
- Gestion du cycle de vie des outils de cyberdéfense : un levier de performance pour les entreprises









