Les entreprises qui souhaitent exploiter leurs données utilisent, aujourd'hui, Hadoop d'une manière ou d'une autre. Cependant, la valorisation des données a entraîné un foisonnement de problématiques qui nécessitent des réponses technologiques aussi différentes les unes que les autres. Hadoop a beau être le socle technique du Big Data, il n’est pas capable à lui seul de répondre à toutes ces problématiques.
Initiation à l’écosystème Hadoop

A chaque nouvelle problématique, les développeurs sont obligés de coder de nouveaux modules, ce qui en plus d’être frustrant à mettre en production, réduit la productivité des équipes de développement, qui passent désormais leur temps plus au débogage du code qu’au développement.
C’est pour combler ces lacunes qu’un ensemble de technologies regroupées sous le nom d’écosystème Hadoop a été développé. L’écosystème Hadoop fournit une collection d’outils et technologies spécialement conçus pour faciliter le développement, le déploiement et le support des solutions Big Data. L’objectif de cet article est double :
- passer en revue la fonction de chacun de ces outils de l’écosystème.
- annoncer la sortie prochaine (prévue pour Mars/Avril) de l’ouvrage intitulé « Maîtrisez l’utilisation de l’écosystème Hadoop : Initiation à l’écosystème Hadoop» Editions Eyrolles, qui les traite de façon exhaustive.
L’ouvrage a pour but d’aider tout professionnel à utiliser de façon professionnelle 18 technologies clé de l’écosystème Hadoop à savoir : Spark, Hive, Pig, Impala, ElasticSearch, HBase, Lucene, HAWQ, MapReduce, Mahout, HAMA, TEZ, Phoenix, YARN, ZooKeeper, Storm, Oozie, et Sqoop.
En attendant la sortie officielle de l’ouvrage, vous pouvez vous procurer gratuitement un extrait portant sur ElasticSearch. Pour le recevoir directement dans votre boîte mail (30 pages), cliquez sur le lien
La carte heuristique suivante présente de façon globale l’écosystème Hadoop et résume particulièrement bien la structure de l’ouvrage.
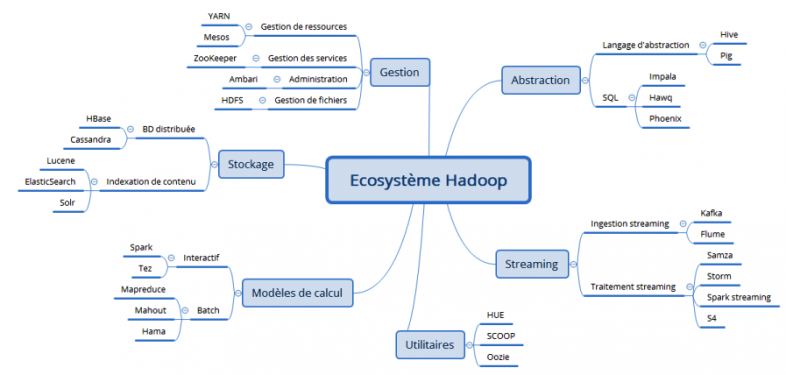
Maintenant passons au vif du sujet
La configuration de base de l’écosystème Hadoop contient les technologies suivantes : Spark, Hive, PIG, HBase, Sqoop, Storm, ZooKeeper et Oozie.
- Spark
Avant d’expliquer ce que c’est que Spark, rappelons que pour qu’un algorithme puisse s’exécuter sur plusieurs nœuds d’un cluster Hadoop, il faut qu’il soit parallélisable. Ainsi, on dit d’un algorithme qu’il est « scalable » s’il est parallélisable (et peut donc profiter de la scalabilité d’un cluster). Hadoop est une implémentation du modèle de calcul MapReduce. Le problème avec le MapReduce est qu’il est bâti sur un modèle de Graphe Acyclique Direct. En d’autres termes, l’enchaînement des opérations du MapReduce s’exécutent en trois phases séquentielles directes et sans détour (Map -> Shuffle -> Reduce), aucune phase n’est itérative (ou cyclique).
Le modèle acyclique direct n’est pas adapté à certaines applications, notamment celles qui réutilisent les données à travers de multiples opérations, telles que la plupart des algorithmes d’apprentissage statistique, itératifs pour la plupart, et les requêtes interactives d’analyse de données. Spark est une réponse à ces limites, c’est un moteur de calcul qui effectue des traitements distribués en mémoire sur un cluster.
Autrement dit, c’est un moteur de calcul in-memory distribué. Comparativement au MapReduce qui fonctionne en mode batch, le modèle de calcul de Spark fonctionne en mode interactif, c’est à dire, monte les données en mémoire avant de les traiter et est de ce fait très adapté au traitement de Machine Learning.
- Hive
Hive est une infrastructure informatique similaire au Data Warehouse qui fournit des services de requêtes et d’agrégation de très gros volumes de données stockées sur un système de fichier distribué de type HDFS. Hive fournit un langage de requête basé sur le SQL (norme ANSI-92) appelé HiveQL (Hive Query Language), qui est utilisé pour adresser des requêtes aux données stockées sur le HDFS.
Le HiveQL permet également aux utilisateurs avancés/développeurs d’intégrer des fonctions Map et Reduce directement à leurs requêtes pour couvrir une plus large palette de problèmes de gestion de données. Lorsque vous écrivez une requête en HiveQL, cette requête est transformée en job MapReduce et soumis au JobTracker pour exécution par Hive. Voici un exemple de requête écrite en HiveQL. Trouver la température maximale par année.
USE default ;
CREATE TABLE records (year string, temperature INT, quality INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’ ;
LOAD DATA LOCAL ‘data/sample.txt’ OVERWRITE INTO TABLE records ;
SELECT year, MAX(temperature) FROM records WHERE temperature !=9999 AND (quality == 0 OR quality == 1) GROUP BY year ;
Téléchargez cette ressource

Guide de Threat Intelligence contextuelle
Ce guide facilitera l’adoption d’une Threat Intelligence - renseignement sur les cybermenaces, cyberintelligence - adaptée au "contexte", il fournit des indicateurs de performance clés (KPI) pour progresser d' une posture défensive vers une approche centrée sur l’anticipation stratégique
Les articles les plus consultés
A travers cette chaîne
A travers ITPro
Les plus consultés sur iTPro.fr
- Cyber risques et IA : 78% des RSSI pointent une déconnexion inquiétante des dirigeants
- IA agentique dans le delivery : sortir du bruit, entrer en production
- IA au travail : productivité en hausse, lien humain en recul
- La souveraineté numérique commence par avoir le choix de son infrastructure
Articles les + lus

Attaques IA : un Active Directory peut être compromis en 40 minutes

Au-delà du polling: pourquoi la surveillance des systèmes hérités devient un risque pour l’entreprise
La souveraineté numérique commence par avoir le choix de son infrastructure

Réforme de la facturation électronique : une préparation largement théorique

Cryptographie post-quantique : le Campus Cyber publie deux guides clés pour accélérer la transition des entreprises
À la une de la chaîne Enjeux IT
- Attaques IA : un Active Directory peut être compromis en 40 minutes
- Au-delà du polling: pourquoi la surveillance des systèmes hérités devient un risque pour l’entreprise
- La souveraineté numérique commence par avoir le choix de son infrastructure
- Réforme de la facturation électronique : une préparation largement théorique
- Cryptographie post-quantique : le Campus Cyber publie deux guides clés pour accélérer la transition des entreprises



