Vous connaissez certainement l’angoisse que ressentent les métiers lorsque la réponse aux questions qu’ils se posent prend trop de temps. Vous travaillez sur des projets de reporting, Business Intelligence, Big Data et vous avez du mal avec vos requêtes ? Vos bases de données SQL prennent trop de temps pour s’exécuter ? Vos requêtes SQL sont trop lentes ? Vous souhaitez améliorer la performance de vos requêtes SQL ?
Trois pratiques pour doper vos requêtes SQL en 2020

Cette chronique a été rédigée pour vous. Dans cette chronique, nous allons vous montrer 3 approches à utiliser pour doper efficacement la performance de vos requêtes SQL.
Pourquoi avez-vous du mal avec vos requêtes SQL ?
A ce stade, vous savez que la baisse des coûts de stockage des données dans Hadoop fait du HDFS l’option la plus profitable en termes de coûts financiers pour le stockage et le traitement des données. Traditionnellement, lorsqu’on est parvenu à stocker les données dans un Data warehouse, l’interrogation des données consiste souvent à exécuter des requêtes SQL sur le serveur. Ainsi, l’interrogation classique de données se fait à l’aide du SQL.
Le problème c’est que de base, le SQL est un langage ensembliste. Son exécution est très appropriée pour l’interrogation des données qui entretiennent des liens métiers forts. Lorsqu’il est utilisé dans un environnement distribué tel qu’un cluster Hadoop, les problèmes de latence qu’on observe partout dans les projets Big Data sont alors inévitables.
En réalité, l’interrogation efficace des données en environnement Big Data et dans un cluster Hadoop en particulier suit un ensemble de principes que vous devez connaître et respecter scrupuleusement si vous souhaitez garder vos métiers contents.
Il existe 3 grandes approches d’interrogation de données en Big Data. Ce sont ces 3 approches qui structurent cette chronique :
- les Moteur SQL sur Hadoop :
l’exécution des jobs sur Hadoop en utilisant le SQL ou un langage similaire (nativement ou pas)
- le SQL natif sur Hadoop :
l’exécution native du code SQL directement sur le HDFS sans aucune transformation en job de calcul massivement parallèle
- les Moteurs relationnels distribués sur Hadoop :
l’utilisation d’un SGBD MPP (Massively Parallel Processing) tel que Teradata ou GreenPlum qui est capable d’exécuter le SQL sur un cluster
Les bases de l’interrogation des données en Big Data
Avant toute plongée en eaux profondes, revenons sur les fondements de l’interrogation de données à large échelle. Vous devez savoir que dans l’interrogation classique de données, ce sont des requêtes ensemblistes, des opérations d’algèbres linéaires telles que la projection, l’union, l’intersection, les jointures, qui sont exécutées sur la base de données à travers le SQL. En environnement distribué par contre, l’interrogation des données repose sur ce qu’on appelle un modèle de calcul.
D’une façon générale, un modèle de calcul est un modèle algorithmique, c’est-à-dire une façon de penser le découpage d’une requête en tâches exécutables dans un ordinateur. En environnement distribué comme dans un cluster Hadoop, le modèle de calcul est un modèle algorithmique qui permet de découper les requêtes en tâches indépendantes qui s’exécutent simultanément dans le cluster.
En effet, pour qu’une requête profite du parallélisme offert par un cluster, il faut que le modèle de calcul qui permet de traduire cette requête en tâches respecte 2 conditions :
- il faut qu’il soit capable de découper les requêtes en tâches indépendantes.
Ainsi, chaque tâche n’entretiendra aucun lien avec les autres tâches et pourra s’exécuter indépendamment sur un nœud du cluster. La montée à l’échelle se fera alors simplement par augmentation du nombre des tâches et/ou du nombre de nœuds dans le cluster. C’est d’ailleurs cette condition d’indépendance qui différencie le traitement massivement parallèle d’un cluster du traitement multi-threading.
- Il faut que le modèle soit exécutable sur les CPU.
En effet, conceptuellement parlant, il peut être simple de définir la solution à un problème. Mais la solution ainsi conçue peut ne pas être pratique. Le modèle de calcul doit pouvoir s’exécuter dans le cluster, tout en tenant compte des contraintes de ressources, de haute disponibilité, de tolérance aux pannes, des habilitations des utilisateurs et de sécurité.
Le MapReduce est le modèle de calcul de base utilisé dans l’interrogation des données en environnement distribué (dans un cluster). Cela signifie que par défaut, quand vous lancez une requête sur un cluster Hadoop, cette requête est transformée en job MapReduce et exécutée sur le cluster. Le MapReduce est un modèle très simple qui découpe l’exécution d’une requête en 3 phases interdépendantes : le Map, le Shuffle et le Reduce. Ainsi, toute requête exécutée dans un cluster passe par 3 phases : une phase Map, où les données sont transformées en paires de <clés ; valeurs>, une phase Shuffle, où les paires ainsi obtenues sont triées, et une phase Reduce où les paires triées sont agrégées selon une fonction d’agrégation (la SOMME, MOYENNE, etc.). La figure résume mieux l’exécution d’une requête selon le modèle de calcul MapReduce.
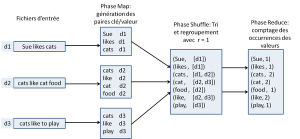
A cause de sa simplicité, le MapReduce est à la base de quasiment tous les modèles de calcul utilisés actuellement pour exécuter des requêtes sur le cluster. A cette phrase, vous vous demandez peut-être :
« Juvénal, si le MapReduce suffit pour gérer l’exécution des requêtes, pourquoi la problématique d’interrogation de données en Big Data se pose-t’elle alors ? »
Si la problématique se pose, c’est pour deux raisons simples :
Problème #1 : Le MapReduce n’est pas adapté à tous types de requêtes. Par exemple, les requêtes relatives aux travaux d’analyse de données (Machine Learning, Data Science, etc…), très itératifs pour la plupart, sont très difficilement parallélisable et ne peuvent pas [facilement] s’exécuter en MapReduce.
Problème #2 : L’écriture des jobs MapReduce n’est pas à la portée des métiers. En effet, l’écriture d’une requête en MapReduce demande l’utilisation d’un langage évolué tel que Java ou Scala. De plus, elle nécessite la connaissance poussée de la programmation distribuée. Les personnes qui exécutent les requêtes au jour le jour dans une entreprise, ce sont les métiers. Il peut s’agir du contrôleur de gestion qui souhaite avoir le total des ventes du mois, le Product Owner qui souhaite faire de la recette pour son projet, les testeurs, qui souhaitent faire de la qualification fonctionnelle, etc… Tout ce public n’a pas pour compétence de base la programmation distribuée.
C’est principalement pour répondre à ces 2 besoins que de nouvelles approches de traitement de données en environnement distribué et des extensions du MapReduce ont été créées.
Téléchargez cette ressource

État des lieux de la sécurité cloud-native
L’État des lieux de la sécurité cloud-native vous offre une analyse complète des problématiques, des tendances et des priorités qui sous-tendent les pratiques de sécurité cloud-native dans le monde entier. Une lecture indispensable pour renforcer votre stratégie de sécurité dans le cloud. Une mine d’infos exclusives pour élaborer votre stratégie de sécurité cloud-native.
La première approche pour doper vos requêtes SQL en Big Data : les couches d’abstraction
La première approche pour doper vos requêtes SQL en Big Data consiste à rapprocher les utilisateurs métiers du cluster.
Comment ?
Via le SQL. Le SQL est aujourd’hui le langage utilisé par toute personne qui manipule les données. Ainsi, en leur permettant d’utiliser une compétence qu’ils possèdent déjà dans le cluster, ceux-ci peuvent facilement adopter Hadoop. C’est en cela que la première approche intervient.
Techniquement, la première approche d’interrogation des données en environnement distribué consiste à masquer la complexité d’écritures des jobs MapReduce à l’aide d’un langage d’abstraction, notamment le SQL. Pour faire simple, l’utilisateur écrit du code SQL, et en arrière-plan, ce code SQL est transformé en job MapReduce et exécuté sur le cluster.
Tout cela se passe de façon totalement transparente aux yeux des utilisateurs. L’écosystème Hadoop dispose actuellement de 2 langages d’abstraction majeurs pour le MapReduce : Hive et Pig. Bien sûr, vous comprenez que nous ne pouvons pas couvrir Hive et Pig dans cette chronique. Si le sujet vous intéresse, nous vous recommandons la ressource suivante.
La deuxième approche pour doper vos requêtes SQL en Big Data : l’utilisation des moteurs SQL-Natifs
La première approche d’interrogation des données à large échelle dans un environnement distribué, notamment un cluster Hadoop, consiste à utiliser une couche d’abstraction SQL telle que Hive ou Pig qui masque l’exécution du modèle de calcul sur le cluster. Cette couche d’abstraction est nécessaire parce que les utilisateurs les plus récurrents d’un cluster ce sont les métiers et ceux-ci ne sont pas formés sur l’écriture des jobs de bas niveau, distribués comme les jobs MapReduce. La deuxième approche s’éloigne complètement du MapReduce et exécute nativement le SQL sur le cluster sans le transformer en Job MapReduce.
En substance, cette approche emprunte les principes de fonctionnement éprouvés des bases de données parallèles et des SGBDR MPP tels que Teradata pour les appliquer à un cluster Hadoop. L’idée consiste à répliquer une structure de données sur chaque nœud du cluster et y faire résider un deamon (processus) de calcul toujours actif qui exécute le SQL directement sur celle-ci lorsqu’il reçoit la requête. Les outils de l’écosytèmes Hadoop actuellement qui implémentent avec succès cette approche sont Impala, Hive LLAP et Druid.
La troisième approche pour doper vos requêtes SQL en Big Data : l’utilisation des SGBD MPP
Une approche efficace pour pallier les problèmes de latence du MapReduce lors de l’interrogation des données consiste à exécuter nativement le SQL sur le cluster en faisant résider sur chaque noeud un deamon actif en permanence pour l’exécution des requêtes. Impala et Hive LLAP fonctionnent de cette façon. Cette approche fonctionne très bien. Cependant, les moteurs natifs-SQL ne sont pas complètement interactifs. Bien qu’un processus de calcul actif réside en permanence sur chaque nœud du cluster pour améliorer la vitesse des traitements, il n’en demeure pas moins que les traitements sont faits directement sur le HDFS.
Les moteurs natifs SQL sur Hadoop exécutent le SQL directement sur le HDFS. Le choix d’exécuter les requêtes directement sur le HDFS n’est pas anodin. Il permet de profiter de la haute disponibilité et la tolérance aux pannes offerts par celui-ci. Cependant, le HDFS est un système de fichiers batch et en tant que tel, il n’a pas été conçu pour fournir un accès rapide aux données. C’est un système intrinsèquement batch. C’est d’ailleurs pour cette raison qu’un SGBD est souvent privilégié pour la gestion de données au détriment d’un accès direct sur le disque.
De plus, lorsque les données sont accédées directement sur le disque, l’application n’a pas de contrôle sur elles (par exemple, des fichiers peuvent être ajoutés, modifiés ou supprimés du système de fichiers sans notification aux applications qui l’exploitent).
Pour résoudre ces 2 problèmes inhérents au système de fichiers (la latence et le non-contrôle des données), la solution conceptuelle consiste à ajouter un SGBD sur le système de fichiers. Le SGBD accélère l’accès aux données placés sur le système de fichiers et offre des fonctionnalités qui permettent de cadrer la façon dont les données sont utilisées. C’est pour cette raison par exemple que HBase ou Cassandra est utilisé pour le stockage des données au lieu du HDFS. Le SGBD contrôle la structure des données stockées et c’est ce qui lui permet d’être plus rapide sur les accès aux données que leur accès directement via le système de fichiers.
Revenons sur l’interrogation des données. Un SGBD distribué peut être utilisé pour dépasser les limites des moteurs natifs et en même temps offrir l’abstraction dont les utilisateurs ont besoin pour travailler sur le cluster. C’est d’ailleurs cette approche que nous recommandons pour doper vos requêtes SQL en Big Data.
En substance, l’approche des SGBD distribué consiste à utiliser un SGBD MPP qui possède une structure de données propre et qui distribue le traitement des requêtes SQL sur les nœuds du cluster. En somme, cette approche combine l’abstraction d’un moteur SQL sur Hadoop au fonctionnalités de gestion de données d’un SGBD distribué. L’écosystème Hadoop dispose de quelques SGBD distribués, à l’instar de Apache Hawk, Apache Drill, Apache Druid, ou encore VectorH. En dehors des outils de l’écosystème Hadoop, Teradata également fait très bien l’affaire si on a les moyens de s’en procurer et si on sait les cas d’usage appropriés.
Voilà ! Nous espérons que cette chronique vous aura permis de comprendre comment optimiser ou doper vos requêtes SQL en Big Data. En réalité, le SQL n’est pas la seule manière d’interroger les données. Une autre approche utilisée par Google fournit des résultats plus spécifiques.
C’est cette approche qu’elle utilise pour dominer la recherche d’information sur Internet : l’indexation qualifiée de contenu. L’indexation de contenu consiste à créer un index inversé de tous les résultats des requêtes possibles séparément et à identifier parmi eux, celui qui répond à l’intention de recherche derrière la requête.
Nous vous offrons en bonus à cette chronique, un ebook de 30 pages qui vous apprendra à aller au-delà du SQL avec l’indexation de contenu en utilisant ElasticSearch.
Cliquez ici pour télécharger votre copie.
Les articles les plus consultés
A travers cette chaîne
A travers ITPro
Les plus consultés sur iTPro.fr
- Les risques liés à l’essor fulgurant de l’IA générative
- Pourquoi est-il temps de repenser la gestion des vulnérabilités ?
- Reporting RSE : un levier d’innovation !
- De la 5G à la 6G : la France se positionne pour dominer les réseaux du futur
- Datanexions, acteur clé de la transformation numérique data-centric









