Depuis que Facebook a annoncé en 2012, le transfert de son data Warehouse longtemps hébergé sur Oracle vers un cluster Hadoop, les Fortunes 500 (grandes entreprises) ont suivi son exemple en commençant elles aussi à l’adopter, au moins en pilote
Hadoop en 5 points pour les DSI

Hadoop : au delà des PoC
Aujourd’hui, toutes les entreprises qui ont décidé de tirer profit du volume de données qu’elles possèdent utilisent Hadoop d’une façon ou une autre, même si nombre d’entre-elles ne sont pas focalisées sur l’avenir. L’utilisation d’Hadoop se résume encore à des PoC (Proof of Concept) qui n’ont pas beaucoup d’intérêts stratégiques pour l’entreprise.
Beaucoup de DSI s’interrogent : « y a-t-il un réel avantage à transférer ses données sur Hadoop ? », « quel est le retour sur Investissement d’Hadoop ? », « y a-t-il un réel intérêt à utiliser Hadoop ? », tandis que d’autres résistent, pensant qu’Hadoop est juste une tendance qui finira par passer.
Dans cet article, nous allons répondre à ces interrogations, vous proposer une autre perception à l’égard d’Hadoop et vous montrer en 5 points où se situe sa réelle valeur.
1er point : Hadoop représente le paradigme technologique adapté à l’ère numérique
Ces trois dernières décennies ont été témoin d’une explosion sans précédent du volume de données. Il est admis que 90 % des données récoltées depuis le début de l’humanité ont été générées durant ces 2 dernières années.
IDC estimait déjà en 2012 que de 2005 à 2020, le volume de données allait croître d’un facteur de 300, de 130 exa-octets à 40 000 exa-octets, soit 40 trillion de giga-octets, ce qui représente plus de 5200 giga-octets créés pour chaque homme, femme et enfant en 2020. Cisco renchérit ce constat lorsqu’il annonce que le trafic IP global annuel est estimé à 1.3 zetta-octets en 2016.
Cet accroissement dans le trafic réseau est attribué à l’accroissement du nombre des smartphones, tablettes et autres appareils connectés à internet, la croissance des communautés d’utilisateurs Internet, la croissance de la bande passante, la rapidité offerte par les opérateurs de télécommunication, et la prolifération de la disponibilité et de la connectivité du Wi-Fi.
Big Data et Hadoop
C’est pour qualifier cette croissance exponentielle du volume de données créé que le terme « Big Data » a été adopté.
La Big Data, qui a accompagné la révolution de l’usage d’Internet ces dix dernières années a provoqué des changements très profonds dans la société : modèles économiques à coût marginal décroissant, commoditisation de la connaissance, décentralisation du pouvoir de création de l’information, suppression des barrières à l’entrée, ubérisation de la société et Internet des Objets. La capacité à capter toutes ces données et pouvoir efficacement les traiter est devenue facteur essentiel de compétitivité.
Traditionnellement, le paradigme technologique de gestion des données consiste à centraliser le stockage et le traitement des données sur un serveur central dans une architecture client/serveur. Ces données sont gérées dans le serveur par un SGBDR. Le serveur central, ici, est une machine très puissante, conçue sur mesure par des sociétés spécialistes de l’infrastructure informatique comme EMC, Dell ou encore HP. La figure suivante illustre ce paradigme.
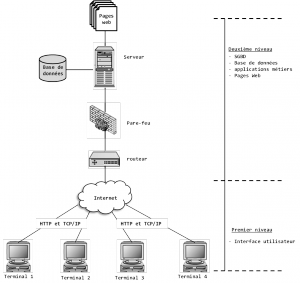
Paradigme technologique traditionnel de gestion des données
Google fait partie des entreprises qui a très tôt ressenti les faiblesses de ce paradigme technologique. En 2002, son directeur général (CEO) de l’époque Eric Schmidt, a envoyé une onde de choc dans toute l’industrie de l’IT en annonçant que Google n’avait aucune intention d’acheter le nouveau serveur d’HP doté du tout dernier microprocesseur Itanium développé par Intel.
Google : la Vision
Dans la vision de Google, avec la baisse des coûts d’ordinateurs tels que prédits par la loi de Moore, le futur du traitement informatique reposerait sur la constitution de Data Centers composés de plusieurs machines commodes (les clusters). Par ce point de vue, Google a introduit un nouveau paradigme technologique qui va progressivement remplacer l’architecture client/serveur classique.
En 2002, cette vision technologique de Google paraissait ridicule, mais aujourd’hui, elle fait sens. En effet, l’échelle de croissance des données surpasse aujourd’hui la capacité raisonnable des technologies traditionnelles, ou même la configuration matérielle typique supportant les accès à ces données.
L’approche proposée par Google consiste à distribuer le stockage des données et à paralléliser leur traitement sur les nœuds d’un cluster. Hadoop est l’implémentation logicielle la plus mature qui permet de mettre en œuvre cette approche. La figure suivante illustre ce nouveau paradigme.
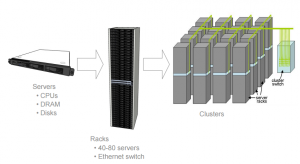
Nouveau paradigme de gestion des données
Clairement, Hadoop s’adresse aux DSI qui souhaitent traiter de façon effective leurs volumes de données tout en profitant de la baisse de coûts des ordinateurs engendrée par l’évolution technologique.
2ème point : Hadoop permet de réduire votre TCO
Le TCO (Total Cost of Ownership, en français Coût Total de possession) est le coût de revient de l’infrastructure du système informatique d’une entreprise. Il prend en compte le coût des ordinateurs, le coût d’acquisition des logiciels, le coût des licences, et le coût de support de cette infrastructure (salaire des personnes qui travaillent pour maintenir l’infrastructure en marche, coût d’électricité pour faire tourner l’infrastructure…).
Le TCO donne une indication sur le poids du système informatique dans la structure de coût globale de l’entreprise, et sert ainsi d’indicateur utile à la prise de décision lors des affectations de budget et des achats informatiques.
Loi de Moore
En 1965, le co-fondateur et actuel PDG d’Intel, Gordon Moore, fait le constat selon lequel « le nombre de transistors des microprocesseurs double tous les 18 mois à coût constant ». Plus tard, cette affirmation sera qualifiée de loi de Moore.
En prédisant que le nombre de transistors dans les ordinateurs allait doubler tous les 18 mois, Moore estimait que la performance de l’Infrastructure Informatique (fréquence processeur, Mémoire RAM,…) allait doubler tous les 18 mois à un coût presque identique, ce qui a été constaté et continue d’être constaté aujourd’hui : le coût de la fréquence de traitement des processeurs a considérablement baissé de 400 euros pour 1 GHz en 1978 à 50 euros en 1985, à moins de 4 euros en 1995.
Aujourd’hui, il est à moins d’1 euro. Concrètement, cela veut dire que les entreprises peuvent désormais disposer d’infrastructures informatiques de plus en plus performantes à des coûts de plus en plus bas.
L’infrastructure informatique a toujours été l’une des sources majeures de coûts fixes dans une entreprise. Avec le nouveau paradigme technologique, Hadoop peut être utilisé dans un cluster de machines commodes pour réduire le TCO des DSI tout en bénéficiant des avantages d’un cluster.
3ème point : Hadoop est la solution la plus performante pour traiter vos données
Dans l’approche traditionnelle de gestion de données, qui est encore en vigueur dans beaucoup d’entreprises, la croissance des données se fait par upsizing du serveur, c’est-à-dire par augmentation de la capacité de ses composants. Par exemple, il peut s’agir de l’augmentation de la mémoire, de 32 Go à 64 Go, l’augmentation de la fréquence du processeur, de 3 Ghz à 5 GHz, ou l’augmentation de la capacité de stockage du disque dur de 500 Go à 2 To.
L’upsizing permet au serveur d’être scalable (on parle de scalabilité verticale dans ce cas), mais jusqu’à un certain point. En effet, l’upsizing est rapide à mettre en œuvre et ne demande aucune modification sur l’architecture informatique. Cependant, la scalable qu’elle offre est limitée à la capacité maximale des composants. Les composants informatiques comme la RAM, le microprocesseur, ou encore le disque dur sont limités par des lois de la physique et par le niveau d’évolution technologique. Par exemple, vous ne pouvez actuellement pas trouver sur le marché une barrette RAM de 500 Go. Pour atteindre cette capacité, il vous faut ajouter 8 barrettes de 64 Go, ce que la carte mère des serveurs ne prévoit pas toujours, en raison d’un nombre limité de slots.
Ce raisonnement est valable pour l’upsizing du disque dur et du micro-processeur. Ainsi, l’upsizing augmente la scalabilité du système jusqu’à un certain seuil à partir duquel la performance du système reste stable. Avec la baisse des coûts du matériel informatique, le coût d’acquisition et d’évolution d’un cluster devient plus faible que le coût d’acquisition et d’évolution d’un serveur central.
De plus, le fait de regrouper des machines commodes en cluster permet de bénéficier des effets d’échelle continus. En effet, les clusters sont linéairement scalables, ce qui signifie que la croissance de données se fait non plus par upsizing des composants des machines, mais par augmentation du nombre de nœuds du cluster. Ainsi, dans un cluster, le temps de traitement des données diminue avec l’ajout de nouveaux nœuds : pour une volumétrie de données fixe, doubler le nombre de nœuds du cluster permet donc de diviser par deux le temps de traitement des données.
En d’autres termes, il est moins coûteux à une entreprise d’ajouter un nœud à un cluster que d’ajouter des capacités supplémentaires à un serveur central.
4ème point : Hadoop peut être utilisé comme levier de compétitivité
Eminent auteur et analyste de la Havard Business Review, Nicholas Carr est connu pour avoir bouleversé le marché de l’industrie IT avec son article « Does IT matter ? » (Est ce que l’IT a un rôle ?), écrit sur le constat d’entreprises rendues euphoriques par la découverte du potentiel impact stratégique des technologies sur leur niveau de compétitivité.
L’article fustige la tendance inconsciente qu’ont les entreprises à associer l’évolution technologique à sa valeur stratégique. Selon l’auteur, ce n’est non pas son ubiquité, ni même son niveau de performance qui font d’une ressource un avantage compétitif mais bien sa rareté et le niveau de complexité associée à sa duplication.
Or, l’évolution technologique réduit les coûts d’acquisition de la technologie (la loi de Gordon Moore), ce qui a pour conséquence de la banaliser ou de la « commoditiser« , détruisant ainsi l’avantage concurrentiel qui pouvait en émerger. Même les technologies les plus récentes finissent rapidement par devenir accessibles. Sur ce point, Nicholas Carr a tout à fait raison.
Il est vrai que ce qui détermine finalement la profitabilité et la survie d’une entreprise, c’est sa différence. De la même façon toute technologie qui améliore la productivité d’une entreprise finit rapidement par devenir une commodité grâce à la vitesse des progrès technologiques.
En revanche, il faut relever que cette force qui tend à la rendre commode est aussi une source de compétitivité pour les entreprises qui le comprennent.
En effet, la technologie a toujours été un facteur différenciateur entre les entreprises, comme entre les Etats. Les entreprises qui implémentent en premier une technologie avant qu’elle ne devienne un standard possèdent temporairement un avantage concurrentiel qui peut faire d’elles le leader sur leur marché.
Dans un monde de « destruction créatrice »[1] perpétuelle comme celui du Numérique dans lequel nous vivons actuellement, l’opportunité se situe sur la différence entre la meilleure technologie développée et la technologie actuellement utilisée.
En d’autres termes, ce qui constitue une opportunité, ce sont les avancées technologiques que la société est prête à mettre en œuvre /utiliser. Or, comment savoir si une avancée technologique ou une technologie est prête ? Lorsque celle-ci est transparente à l’utilisateur, ce qui est le cas d’Hadoop.
Les DSI peuvent profiter de la relative nouveauté d’Hadoop sur le marché pour obtenir des avantages compétitifs temporaires. Mais cela ne se fera qu’à une seule condition : que les entreprises cessent de considérer les DSI comme les « directions d’électricité » à l’époque industrielle ; autrement dit que les entreprises cessent de voir la DSI comme un processus support dont le but est créer le système d’information de l’entreprise, mais comme un processus métier dont le but est de faciliter le flux d’information aux clients, employés et actionnaires.
5ème point : Hadoop est mature et est en train de devenir un standard
Dans l’ère numérique, une opportunité se détecte en regardant le secteur de l’économie dans lequel la technologie ou les pratiques utilisées ont une efficacité inférieure aux évolutions technologiques du secteur. En revanche, le timing est important à ce point, car les utilisateurs peuvent ne pas être prêts à utiliser la technologie.
Mais, comment savoir si le marché est prêt pour une avancée technologique ou une technologie ? Lorsqu’elle ne demande pas plus de compétences à l’utilisateur que la technologie qu’elle va remplacer (la transparence à l’utilisateur).
C’est ce principe qui se retrouve derrière la fameuse loi de Metcalfe selon laquelle « la valeur d’un standard est proportionnel au carré du nombre de systèmes qui l’utilise ». Nous pouvons contextualiser cette citation en disant que la valeur d’une technologie est proportionnelle au carré du nombre de personnes qui l’utilise.
En d’autres termes, l’adoption à grande échelle et le succès de Hadoop ne dépendent pas des développeurs, mais des analystes métier. La fondation Apache a compris cela et c’est pourquoi, depuis qu’elle a repris Hadoop en 2009, elle s’évertue à le rapprocher le plus que possible du SQL, et ce pour deux raisons majeures.
Premièrement, parce que le SQL est le langage standard de manipulation et d’interrogation des bases de données actuelles. Ainsi pour devenir un standard, Hadoop doit donner la possibilité aux utilisateurs métier d’utiliser leur langage favori.
Secondement, parce que les entreprises utilisent de plus en plus le HDFS comme répertoire de stockage central pour toutes leurs données. La majorité des outils d’exploitation de ces données (par exemple, Business Objects, Oracle, SAS, Tableau, etc.) s’appuient sur le SQL. Il faut donc des outils capables d’exécuter le SQL directement sur le HDFS.
Aujourd’hui, Hadoop possède tout un écosystème technologique qui facilite son adoption par les utilisateurs et offre la capacité d’exécuter le SQL directement sur le HDFS.
[1] Expression associée à l’économiste Joseph Schumpeter et mentionné dans son livre Capitalisme, Socialisme et Démocratie, éditions Payot, 1942
Téléchargez cette ressource

Rapport Forrester sur les solutions de sécurité des charges de travail cloud (CWS)
Dans cette évaluation, basée sur 21 critères, Forrester Consulting étudie, analyse et note les fournisseurs de solutions de sécurité des charges de travail cloud (CWS). Ce rapport détaille le positionnement de chacun de ces fournisseurs pour aider les professionnels de la sécurité et de la gestion des risques (S&R) à adopter les solutions adaptées à leurs besoins.
Les articles les plus consultés
A travers cette chaîne
A travers ITPro
- ActiveViam fait travailler les data scientists et les décideurs métiers ensemble
- La blockchain en pratique
- L’utilisation des données pour survivre !
- Les projets d’intégration augmentent la charge de travail des services IT
- Intelligence Artificielle : DeepKube sécurise en profondeur les données des entreprises
Les plus consultés sur iTPro.fr
- De la 5G à la 6G : la France se positionne pour dominer les réseaux du futur
- Datanexions, acteur clé de la transformation numérique data-centric
- Les PME attendent un meilleur accès aux données d’émissions de la part des fournisseurs
- Fraude & IA : Dr Jekyll vs. Mr Hyde, qui l’emporte ?
- Gestion du cycle de vie des outils de cyberdéfense : un levier de performance pour les entreprises
Sur le même sujet

ActiveViam fait travailler les data scientists et les décideurs métiers ensemble

Intelligence Artificielle : DeepKube sécurise en profondeur les données des entreprises

La blockchain en pratique

10 grandes tendances Business Intelligence

Les projets d’intégration augmentent la charge de travail des services IT




