

SQL Server : les tendances pour 2008
Tels des Nostradamus de notre temps, les responsables informatiques et administrateurs SQL Server ont besoin de se projeter dans l’avenir pour garantir la pérennité à court et long termes des investissements d’aujourd’hui dans les technologies et les infrastructures.
L’année 2008 s’annonce riche en événements pour la communauté SQL Server. Nous avons donc pensé que quelques prédictions et pronostics, assortis des conseils avisés de quelques experts, vous aideront à choisir la meilleure route possible vers les dernières évolutions technologiques et les nouvelles versions de produits dignes d’intérêt.
| Contenu complémentaire : Des solutions géospatiales pour SQL Server 2008 |
Lire l'article
La démocratisation de la performance de l’entreprise avec PerformancePoint Server 2007
Le système d’information est devenu depuis quelques années un point central pour la croissance des entreprises. Dans un premier temps ces systèmes ont permis de collecter et de traiter l’information tout en optimisant son stockage. Puis dans un second temps, grâce à l’évolution de la puissance des machines, de la capacité disques grandissante, ces données ont pu être croisées et agrégées à des fins analytiques.Nous voyons aujourd’hui fleurir de nombreux projets autour des problématiques « VLDB » (Very Large Data Base). Le traitement de données de masse n’est plus une barrière au grand bénéfice des projets axés sur la Business Intelligence.
| Contenu coplémentaire : Présentation du produit PerformancePoint Server 2007 Les acteurs du décisionnels : http://www.olapreport.com/ |
Lire l'article

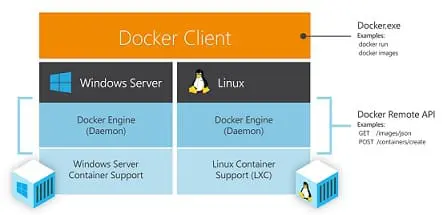
Microsoft Web Plateform Installer
La firme de Redmond vient de sortir la version 1.0 de Microsoft Web Plateform Installer, un outil permettant d’installer et d’optimiser sa plateforme Web.
Ce petit logiciel permet d’installer et de mettre à jour IIS, Visual Web Developer 2008 Express Edition, SQL Server 2008 Express Edition et le framework .NET.
Lire l'article

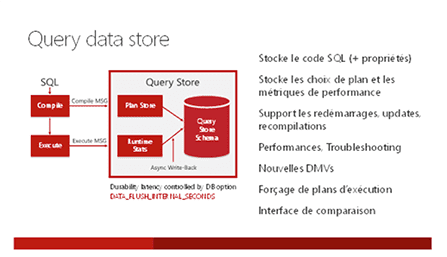
Service Broker
Service Broker offre la possibilité de travailler en mode asynchrone avec une SQL Server en proposant un service de messagerie fiable entre les instances.
SQL Server : l’aide à la migration – partie 2
Deuxième partie de l'article portant sur SSMA, un outil qui facilite SQL Server.
| Contenu complémentaire : La première partie de l'article le site du GUSS Migrer vers SQL Server sans avoir à réécrire le COBOL |
Lire l'article


SQL Assistant 4.0
SoftTree Technologies vient d’annoncer la sortie de SQL Assistant 4.0.
Ce nouveau produit permet de vérifier et d’améliorer la qualité et la précision du code grâce à des outils d’aide à la programmation.
Lire l'article
Un accès sécurisé aux données des rapports
Dans les secteurs de la santé et de la finance, où les applications de base de données traitent fréquemment des informations confidentielles, le recours à l’authentification et au cryptage pour sécuriser l’accès aux données est devenu une pratique courante.
En effet, pour les entreprises soumises à des réglementations spécifiques telles que la loi américaine sur la portabilité et la responsabilité d’assurance médicale HIPAA (Health Insurance Portability and Accountability Act), la sécurisation des données des systèmes de reporting constitue une nécessité absolue. En revanche, dans de nombreux autres secteurs, la sécurité des systèmes de reporting et des bases de données auxquelles ils accèdent reste une priorité secondaire sur les listes de tâches des concepteurs et administrateurs de systèmes, en raison de sa complexité apparente.
Pourtant, ce type de travail n’a nul besoin d’être difficile, en particulier si vous utilisez SQL Server Reporting Services (SSRS) comme système de reporting. Fourni avec Windows Server 2003 ou Windows 2000. Voyons comment configurer SSRS afin de sécuriser l’accès à vos données.
| Contenu complémentaire : Le groupe utilisateurs de SQL Server |
Lire l'article

Microsoft SQL Server 2008 RTM
Le générateur de rapports de Microsoft SQL Server 2008 est à présent disponible en version RTM.
Sa nouvelle interface orientée « utilisateur final », affiche un look à la Office 2007.
Lire l'article
SQL Server : l’aide à la migration – partie 1
Cet article porte sur SSMA, un outil qui facilite SQL Server.
| Contenu complémentaire : le site du GUSS Migrer vers SQL Server sans avoir à réécrire le COBOL |
Lire l'article



Migration des cubes d’Analysis Services 2000 vers Analysis Services 2005
SQL Server 2005 Analysis Services (SSAS) fournit une multitude de raisons attrayantes en faveur d’une mise à niveau à partir de SSAS 2000.
Parmi les nombreuses améliorations, SSAS 2005 offre une plus grande souplesse d’analyse en exposant plus d’attributs de dimensions sous forme d’objets d’analyse. Mais la décision d’une mise à niveau ne va pas sans défis.
| Contenu complémentaire : Hors série spécial SQL Server 2005 L’analyse décisionnelle à l’honneur dans SQL Server 2005 |
Lire l'article

Déconnectez un utilisateur d’une base de données en 2 temps, 3 mouvements
Les développeurs, les ingénieurs en assurance qualité (QA), les non-administrateurs et autres processus SQL Server correspondants. Pour cela, vous pouvez appliquer une procédure en deux étapes toute simple :
1. Identifiez la personne connectée et la base de données qu’elle utilise.
2. Exécutez le script KickUserOut.sql.
| Contenu complémentaire : VERITAS INDEPTH™ pour SQL Server |
Lire l'article

Les plus consultés sur iTPro.fr
- Vers l’Industrie 5.0 : quand l’IA agentique change la donne
- Ready For IT 2026 : IA industrialisée, deepfakes et Prix Start-up au cœur des enjeux
- La chaîne d’approvisionnement, point de rupture récurent du SI
- Ready For IT 2026 : quand l’accélération de l’innovation redessine les priorités des décideurs IT
Articles les + lus

Souveraineté des données : cessons de traiter le symptôme, attaquons-nous aux causes

IA générative en Europe : une adoption massive, mais une gouvernance toujours en retard

Golden records : le socle oublié des projets IA

Avec les Smart Data, les entreprises mènent la danse de l’observabilité moderne

ADI, l’infrastructure de données de Scality pensée pour l’ère de l’IA et de la souveraineté
À la une de la chaîne Data
- Souveraineté des données : cessons de traiter le symptôme, attaquons-nous aux causes
- IA générative en Europe : une adoption massive, mais une gouvernance toujours en retard
- Golden records : le socle oublié des projets IA
- Avec les Smart Data, les entreprises mènent la danse de l’observabilité moderne
- ADI, l’infrastructure de données de Scality pensée pour l’ère de l’IA et de la souveraineté