
Migration des cubes d’Analysis Services 2000 vers Analysis Services 2005
SQL Server 2005 Analysis Services (SSAS) fournit une multitude de raisons attrayantes en faveur d’une mise à niveau à partir de SSAS 2000.
Parmi les nombreuses améliorations, SSAS 2005 offre une plus grande souplesse d’analyse en exposant plus d’attributs de dimensions sous forme d’objets d’analyse. Mais la décision d’une mise à niveau ne va pas sans défis.
| Contenu complémentaire : Hors série spécial SQL Server 2005 L’analyse décisionnelle à l’honneur dans SQL Server 2005 |
Lire l'article

Déconnectez un utilisateur d’une base de données en 2 temps, 3 mouvements
Les développeurs, les ingénieurs en assurance qualité (QA), les non-administrateurs et autres processus SQL Server correspondants. Pour cela, vous pouvez appliquer une procédure en deux étapes toute simple :
1. Identifiez la personne connectée et la base de données qu’elle utilise.
2. Exécutez le script KickUserOut.sql.
| Contenu complémentaire : VERITAS INDEPTH™ pour SQL Server |
Lire l'article



Le respect des règles avec Reporting Services
SQL Server 2005 Reporting Services effectue un travail remarquable pour les rapports chargés d’extraire des données de SQL Server 2005 Analysis Services.
Cet outil connaît son affaire pour fournir l’infrastructure nécessaire au développement de rapports, à la sélection de paramètres et au contrôle des accès aux rapports. Toutefois, Reporting Services a parfois un comportement inattendu ou non souhaité avec les données Analysis Services et vous devez faire preuve d’imagination pour contourner ce type de limitation.
Malheureusement, les solutions de contournement inventives peuvent, dans certains cas, entraîner des modifications du modèle de données ou de la sécurité. Il est préférable de circonscrire autant que possible les exigences sur la couche présentation plutôt que de modifier les modèles de données ou la sécurité simplement afin de faciliter le reporting. Le présent article aborde une situation fréquente au cours de laquelle Reporting Services n’a pas de solution intuitive pour répondre à des exigences particulières concernant un rapport. La solution en trois volets à ce problème fait appel à des fonctionnalités disponibles dans Reporting Services et Analysis Services pour se cantonner entièrement à la couche présentation des rapports.
L’exemple de projet Reporting Services, lequel s’appuie sur la base de données exemple AdventureWorks, est téléchargeable à l’adresse http:// www.itpro.fr (Club Abonnés). Le projet en question comporte deux fichiers .rdl : AW_Sample_Problem.rdl, qui affiche le rapport du problème, et AW_Sample.rdl, qui présente la solution. J’aimerais en profiter pour remercier Al Ludlow, développeur spécialiste des data warehouses chez CIBER, pour avoir aimablement créé la majeure partie de la solution.
| Contenu Complémentaire : Tout sur Reporting Services Le groupe utilisateur de SQL Server |
Lire l'article

La sécurité de SQL Server 2005 en 10 étapes
Le produit SQL Server 2005 de Microsoft est un sécuriser les composants de l’infrastructure, notamment les serveurs de base de données. Cette stratégie met l’accent sur la protection de la périphérie, du réseau, des hôtes, des applications, des données et sur les défenses physiques. Le présent article expose 10 étapes à respecter avant, pendant et après l’installation de SQL Server 2005, afin de blinder votre infrastructure avec une défense en profondeur.

Prenez le contrôle de vos rapports avec ReportViewer
Visual Studio 2005 constitue la clé de voûte de toutes ces fonctionnalités. Il s’agit d’un outil souple, utilisable dans les Windows Forms et formulaires Web pour afficher deux types de rapports. Le premier type est un rapport côté serveur, qui nécessite un serveur de rapports SSRS.
Ce dernier fournit les valeurs des paramètres du rapport, crée les datasets et assure le rendu. Le contrôle ReportViewer affiche ensuite le rapport rendu dans une fenêtre d’application. Lorsque vous créez des rapports côté serveur, vous utilisez le mode de traitement distant. Le deuxième type est un rapport local. Ces rapports sont distribués en tant que partie intégrante d’une application et ne requièrent pas de serveur SSRS. Toutefois, le fait de s’affranchir du lien à un serveur de rapports a un coût. L’application doit fournir les valeurs pour les paramètres du rapport et créer tous les datasets. Le contrôle ReportViewer assure le rendu du rapport. Lorsque vous optez pour cette approche, vous utilisez le mode de traitement local.

La chute des cookies ?
La gestion des sessions utilisateur sur plusieurs fermes Web et plateformes demeure l’un des défis suprêmes du développement de sites Web à haute disponibilité. Comme l’explique l’article « Une recette pour remplacer les variables de session » (Club Abonnés, SQL Server Magazine décembre 2006), l’utilisation conjointe des cookies, des procédures stockées SQL Server, d’un générateur de GUID et de paramètres d’URL. Certains développeurs évitent les paramètres d’URL car ils sont transmis de manière visible d’une page à l’autre. Ils leur préfèrent le passage de valeurs au moyen de champs masqués. Dans les deux cas, les résultats ne sont pas sécurisés. Par conséquent, les valeurs passées d’une page à l’autre doivent être les plus obscures possibles.
Le passage de toute information présente un risque potentiel pour la sécurité. J’aime utiliser les GUID car ils ne révèlent pas réellement d’informations utiles pour les pirates potentiels et permettent malgré toute la persistance de la session pendant tout le temps nécessaire. Le présent article va aborder les techniques que j’emploie pour créer un gestionnaire de sessions sans cookies basé sur SQL Server. Il présente également le fonctionnement du gestionnaire de sessions et différentes manières de l’employer.

Construisez un système ETL simple avec SSIS
Vous savez probablement que vous pouvez utiliserun entrepôt de données (data warehouse).Mais comment allez-vous procéder ? À quoi ressemble une application ETL ?SSIS se targue de proposer tellement de nouveautés que les nouveaux venus ont l’impression d’avoir déballé un puzzle sur leur bureau. Il est difficile d’assembler les pièces sans avoir sous les yeux une vue d’ensemble du résultat final, notamment lorsque les pièces d’autres puzzles viennent jouer les trouble-fêtes ou lorsque certains éléments manquent !
L’objectif de cet article est justement de fournir la vue d’ensemble nécessaire : nous allons aborder les opérations élémentaires de conception et de construction de packages SSIS, et ainsi fournir les bases pour l’étude ultérieure des techniques de chargement incrémentiel concernant les dimensions et faits, ainsi que les variables, les scripts et l’audit de base des processus.


Actu SQL 28
La bataille fait rage sur le marché des serveurs, faisant perdre son latin au Gartner Group. Le cabinet d’analyse a ré-estimé la progression du marché à la baisse plaçant IBM devant HP. En mai dernier, le cabinet d’analyse avait indiqué l’inverse. A présent, IBM fait 29.4 % des revenus totaux du premier trimestre 2008 contre […]
Lire l'article
Placez les données de vos cubes sur le devant de la scène
une autre perspective de leurs données. Cette capacité peut s’avérer importante lorsque les rapports doivent afficher un grand nombre de mesures et se servent des dimensions en tant que tranches de données.
Par exemple, un rapport qui présente plusieurs mesures pour un seul employé ou produit n’a pas besoin de reprendre cette même information sur les lignes ou dans les colonnes. Par conséquent, nous allons voir comment placer les mesures sur les lignes et une autre dimension, Time, dans les colonnes, tout en réalisant les tranches à partir d’une autre dimension. Nous allons également expliquer comment paramétrer une requête MDX et appliquer un formatage aux valeurs.
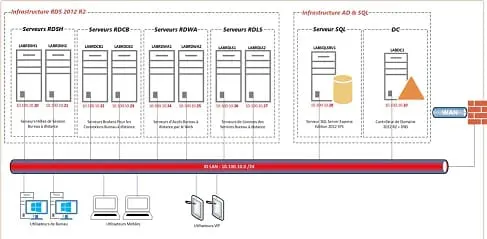
Reporting Services : Conseils et astuces
Le choix et l’installation de SQL Server Reporting Services (SSRS) constituent uniquement la première étape visant à satisfaire la multitude des consommateurs de rapports présents dans votre entreprise. Il vous reste maintenant à produire des rapports éblouissants qui tirent parti des fonctionnalités avancées, afin d’afficher les données conformément à la myriade d’attentes des utilisateurs, sans pour autant délaisser vos autres tâches.
Cet article propose quelques conseils et astuces pour créer des rapports à la fois utiles et souples, qui s’exécutent de manière appropriée. Il indique également un échantillon d’outils tierce partie qui vous permettront d’étendre les fonctionnalités de SSRS.

Analyse décisionnelle : gagnez le gros lot
Depuis quelque temps, la majorité des grandes entreprises se tournent vers des plates-formes d’SQL Server 2005 pour essayer de gagner à la loterie puisse fort ressembler à une simple activité récréative, vous serez capable de transposer directement ces techniques à vos projets métier, comme je l’ai fait pour de nombreux scénarios de sécurité sociale. Bien souvent, les exercices amusants constituent la meilleure approche pour maîtriser des outils et technologies intimidants. En outre, autre avantage connexe, cet article pourrait tout simplement vous rendre terriblement riche.
Lire l'article
actu SQL sem 23
Fin mai, s’est tenue la dernière réunion du GUSS (Groupe des utilisateurs de le décisionnel ! D’abord un petit retour sur le « pourquoi » du décisionnel, avant de s’engouffrer au fur et à mesure dans son évolution et l’offre de Microsoft. Cette session – panorama découverte de la Business Intelligence avec SQL Server – […]
Lire l'article

Prenez le contrôle de vos rapports avec ReportViewer, 2e partie
Comme vous avez pu le découvrir dans la 1ère partie de cet article, le contrôle ReportViewer dees paramètres du rapport. Dans la 1ère partie de cet article, j’expliquais comment créer et afficher un rapport local en utilisant principalement la programmation « drag-and-drop » (glisser-déplacer) pour créer le dataset.
Nous allons maintenant voir comment écrire du code servant à demander les paramètres du rapport et à fournir le dataset, ce qui vous ouvrira des possibilités infinies concernant les types de rapports que vous pouvez créer. Par exemple, il est possible de créer une application qui stocke les définitions de rapport local dans des fichiers externes, afin que vous puissiez ajouter de nouveaux rapports ou mettre à jour des rapports existants sans recompiler et redistribuer l’application.

Validation Intelligente des données
Lorsqu’une personne vous demande de décrire les données de votre entreprise, d’un système précis ou d’une base de données spécifique, combien de fois n’avez-vous pas répondu en mettant l’accent sur la taille du stockage, le taux de croissance, le nombre de tables ou le nombre de lignes ?Ces caractéristiques sont certes importantes pour la conception et la gestion d’une solution efficace et maintenable, mais je vous propose de ne pas limiter vos réponses à la quantité ou au volume, mais également d’inclure une caractérisation de la qualité des données. Après tout, ce n’est pas la quantité des données qui importe, mais leur qualité. Une entreprise peut avoir la plus grande base de données au monde, avec le taux de croissance le plus impressionnant, mais si elle ne peut quantifier la qualité de ses données, celles-ci n’ont aucune utilité.
Le terme « validation intelligente des données » décrit le concept consistant à configurer l’environnement de base de données et de traitement afin d’appliquer automatiquement la validation. Lorsque vous concevez, mettez en oeuvre et gérez vos propres bases de données, vous devez prendre en compte plusieurs aspects essentiels de leur conception : la propriété des données, leur intendance, leurs définitions, leur modélisation, leur normalisation, les valeurs NULL et les types de données, ou encore le nettoyage et l’intégrité des données.
À mesure que vous découvrirez ces aspects tout au long de l’article, rappelez- vous qu’il n’existe rien d’absolu en matière d’options de conception et d’implémentation. Au contraire, vous devez considérer systématiquement les fonctionnalités, avantages et compromis de chaque aspect par rapport à votre environnement spécifique. Si vous gardez cette règle à l’esprit tout au long de votre lecture, vous trouverez des tonnes d’idées pour accroître la qualité de vos données en mettant en oeuvre des stratégies intelligentes de validation de ces dernières.
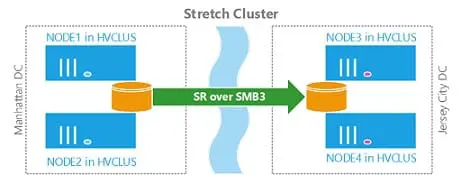
Optimisation des bases de données SQL Server : l’exploitation
Votre modèle des données est parfait : justement normalisé et très légèrement dénormalisé par des techniques fiables et pour des données dont il est prouvé que cela apporte un gain significatif. Vos requêtes sont optimisées et les serveurs, tant logiques que physiques, comme leurs environnements sont taillés, dimensionnés, mesurés, configurés pour le volume de données et de transactions à subir. Enfin, vous avez pensé au découpage de vos espaces de stockage, choisi vos disques et constitué vos agrégats en conséquence… Pourtant il vous manque une brique pour parfaire votre oeuvre : penser l'exploitation de vos données au quotidien, c'est là SQL Server sur le site communautaire de developpez.com, un internaute postait un remarquable message. Il avait une procédure complexe longue et coûteuse en traitement qui importait des données dans une base, avec une planification quotidienne de nuit. Un matin quelle ne fût pas sa stupeur de constater que cette procédure qui durait habituellement un peu plus d'une heure, n'était pas encore terminée. Il attendit donc la fin du traitement et constata que ce dernier avait mis près de 10 heures, soit 8 fois plus qu'ordinairement. Que s'était-il passé ?
| Contenu complémentaire Numéro hors série : Gestion et optimisation des environnements multi bases de données Le site du groupe utilisateurs de SQL Server : le GusS |
Lire l'article

Optimisation des bases de données SQL Server Troisième partie
TROISIÈME PARTIE : LE MODÈLE DE DONNÉES
Optimiser une base de données simplement par la qualité de son modèle est une chose simple, très efficace et à coût nul... Voila qui devrait intéresser beaucoup de monde. Or c'est souvent l'inverse qui se passe : le peu d'attention apportée au modèle, le peu de précaution dans le choix des types de données, le peu de respect des formes normales sont autant d'icebergs qui ne vont pointer leurs nez qu'au moment une base de données à raison d'une table pour un fichier est un échec assuré dont beaucoup d'éditeurs de solutions informatiques ont fait les frais.
Ce nouvel article a donc pour but de vous faire comprendre ce que sont les données, les types de données et la modélisation dans la perspective d'optimisation d'une base et donc d'un serveur. Toute application avec une forte implication de SGBDR commence par une modélisation des données. La qualité d'un modèle de données, ne se fera sentir que lorsque ce dernier sera mis à l'épreuve du feu, qui dans l'univers des SGBDR consiste à farcir ses tables qu'une quantité phénoménale de données et jouer les requêtes les plus fréquentes afin d'en mesurer les temps de réponse. Or cette phase est rarement entreprise en test. Elle l'est généralement en production.
C'est là qu'est l'os, hélas1, car il est déjà trop tard ! Lorsqu'un modèle de données est établi, et que le poids du volume des données se fait sentir, alors tenter de le remodéliser pour gagner des performances est un chalenge difficile : les évolutions du schéma conduisent à des migrations de données importantes (donc risquées) et des modifications d'interfaces conséquentes (donc du code à récrire). Lorsqu'il s'agit d'une base de données volumineuse, l'inertie des données peut être telle que l'alternative est s'adapter avec un coût de modification élevé ou mourir. C'est pourquoi un modèle de données bâclé présente la particularité d'avoir un coût très élevé lorsqu'il doit être rectifié, alors qu'un modèle peaufiné présente un coût quasi nul si l'on utilise l'outil adéquat et l'homme d'expérience.
Malheureusement, les français ont beau avoir inventé une méthode de modélisation d'une grande simplicité (MERISE2) il n'en demeure pas moins que peu d'informaticiens savent modéliser les données de manière intelligente. Bref, ce sont de ces écueils que je veux aujourd'hui vous entretenir, et pour cela, j'ai découpé en différentes parties le présent article. La première traite des types de données, la seconde des clefs, la troisième des tables et la quatrième de la normalisation.
Les plus consultés sur iTPro.fr
- Vers l’Industrie 5.0 : quand l’IA agentique change la donne
- Ready For IT 2026 : IA industrialisée, deepfakes et Prix Start-up au cœur des enjeux
- La chaîne d’approvisionnement, point de rupture récurent du SI
- Ready For IT 2026 : quand l’accélération de l’innovation redessine les priorités des décideurs IT
Articles les + lus

Souveraineté des données : cessons de traiter le symptôme, attaquons-nous aux causes

IA générative en Europe : une adoption massive, mais une gouvernance toujours en retard

Golden records : le socle oublié des projets IA

Avec les Smart Data, les entreprises mènent la danse de l’observabilité moderne

ADI, l’infrastructure de données de Scality pensée pour l’ère de l’IA et de la souveraineté
À la une de la chaîne Data
- Souveraineté des données : cessons de traiter le symptôme, attaquons-nous aux causes
- IA générative en Europe : une adoption massive, mais une gouvernance toujours en retard
- Golden records : le socle oublié des projets IA
- Avec les Smart Data, les entreprises mènent la danse de l’observabilité moderne
- ADI, l’infrastructure de données de Scality pensée pour l’ère de l’IA et de la souveraineté